Cómo raspar las reseñas de productos de Amazon detrás de un inicio de sesión
Cómo Extraer Comentarios de Productos de Amazon Detrás de un Inicio de Sesión
Amazon es el sitio web de comercio electrónico más popular para los scraper de la web, con miles de millones de páginas de productos siendo extraídas cada mes.
También alberga una vasta base de datos de reseñas de productos, que pueden ser muy útiles para la investigación de mercado y el monitoreo de competidores.
Puedes extraer datos relevantes del sitio web de Amazon y guardarlos en una hoja de cálculo o en formato JSON. Incluso puedes automatizar el proceso para actualizar los datos regularmente.
Scrapear las reseñas de productos de Amazon no siempre es sencillo, especialmente cuando se requiere inicio de sesión. En esta guía, aprenderás cómo scrapear las reseñas de productos de Amazon detrás de un inicio de sesión. Aprenderás el proceso de inicio de sesión, la extracción de datos de las reseñas y la exportación de las mismas a un archivo CSV.
Sin más preámbulos, empecemos.
Requisitos previos y configuración del proyecto
Utilizaremos la biblioteca Node.js Puppeteer para scrapear las reseñas de Amazon. Asegúrate de tener Node.js instalado en tu sistema. Si no lo tienes, ve al sitio web oficial sitio web de Node.js e instálalo.
Después de instalar Node.js, instala Puppeteer. Puppeteer es una biblioteca de Node.js que proporciona una API amigable de alto nivel para automatizar tareas e interactuar con páginas web dinámicas.
Ahora, instalemos y configuremos Puppeteer.
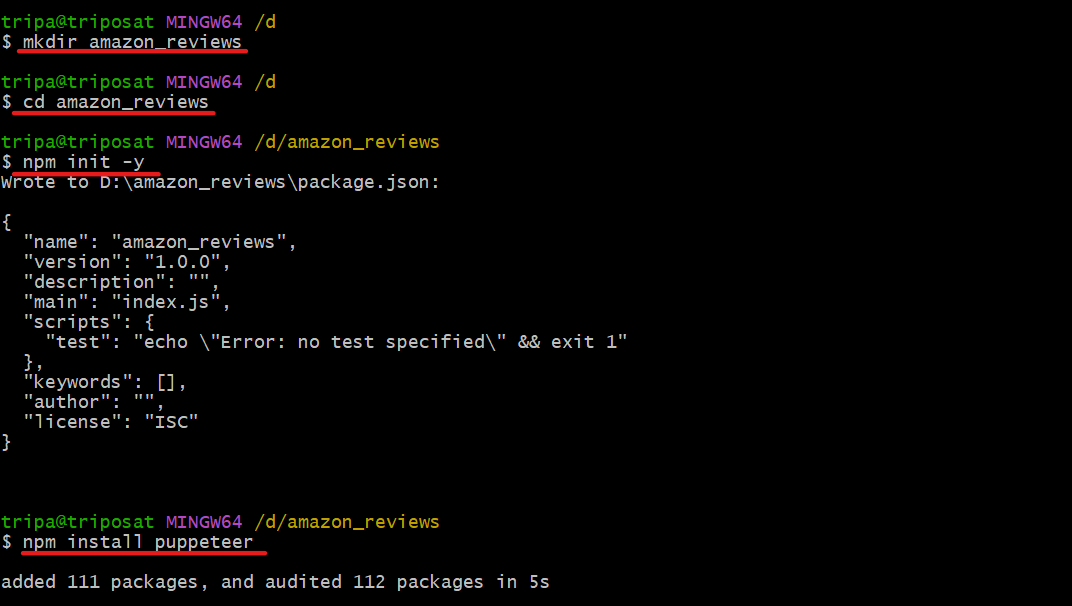
Abre una terminal y crea una nueva carpeta con el nombre que desees. (En mi caso, es amazon_reviews).
mkdir amazon_reviewsCambia tu directorio actual a la carpeta creada anteriormente.
cd amazon_reviewsGenial, ahora estás en el directorio correcto. Ejecuta el siguiente comando para inicializar el archivo package.json:
npm init -yFinalmente, instala Puppeteer usando el siguiente comando:
npm install puppeteerAsí es como se ve el proceso:
Ahora, abre la carpeta en cualquier editor de código y crea un nuevo archivo JavaScript (index.js). Asegúrate de que la jerarquía se vea así:
Todo está configurado correctamente. Ahora estamos listos para codificar el scraper.
Nota: Asegúrate de tener una cuenta en Amazon para poder seguir con el resto de este tutorial.
Paso 1: Obtener acceso a la página pública
Scrapearás las reseñas del producto que se muestra a continuación. Extraerás el nombre del autor, el título de la reseña y la fecha.
Aquí está la URL del producto: https://www.amazon.com/ENHANCE-Headphone-Customizable-Lighting-Flexible/dp/B07DR59JLP/
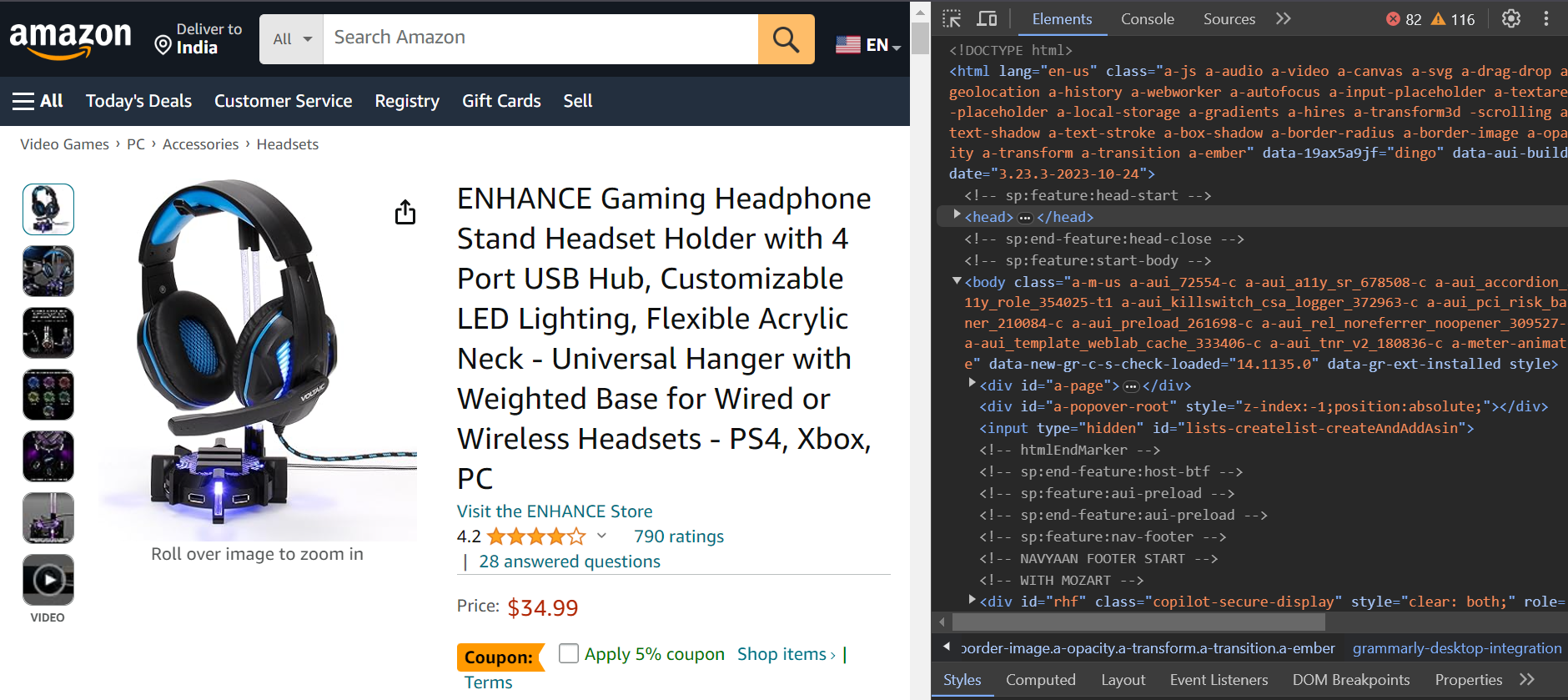
Primero, iniciarás sesión en Amazon y luego te redirigirás a la URL del producto para scrapear las reseñas.
Paso 2: Scrapear detrás del inicio de sesión
El proceso de inicio de sesión en varias etapas de Amazon requiere que los usuarios ingresen su nombre de usuario o correo electrónico, hagan clic en un botón Continuar para ingresar su contraseña y finalmente la envíen. Tanto el campo de nombre de usuario como el de contraseña suelen estar en diferentes páginas.
Para ingresar la dirección de correo electrónico, usa el selector input[name=email].
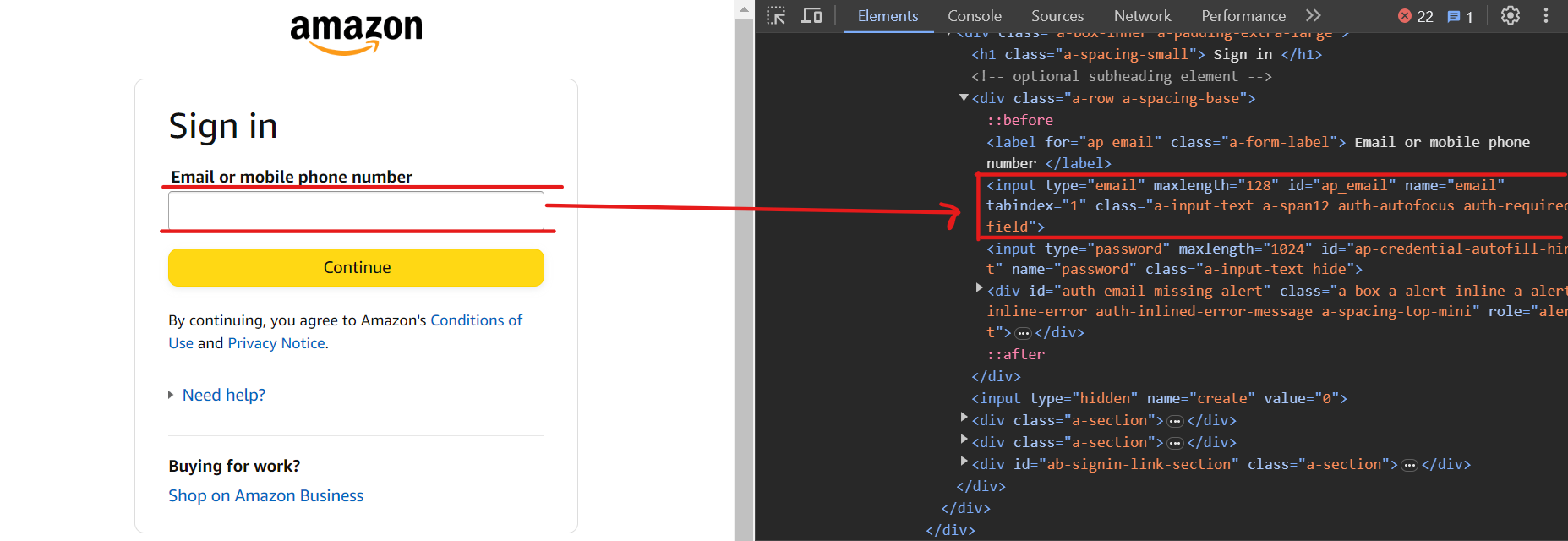
Ahora, haz clic en el botón Continuar usando el selector input[id=continue].
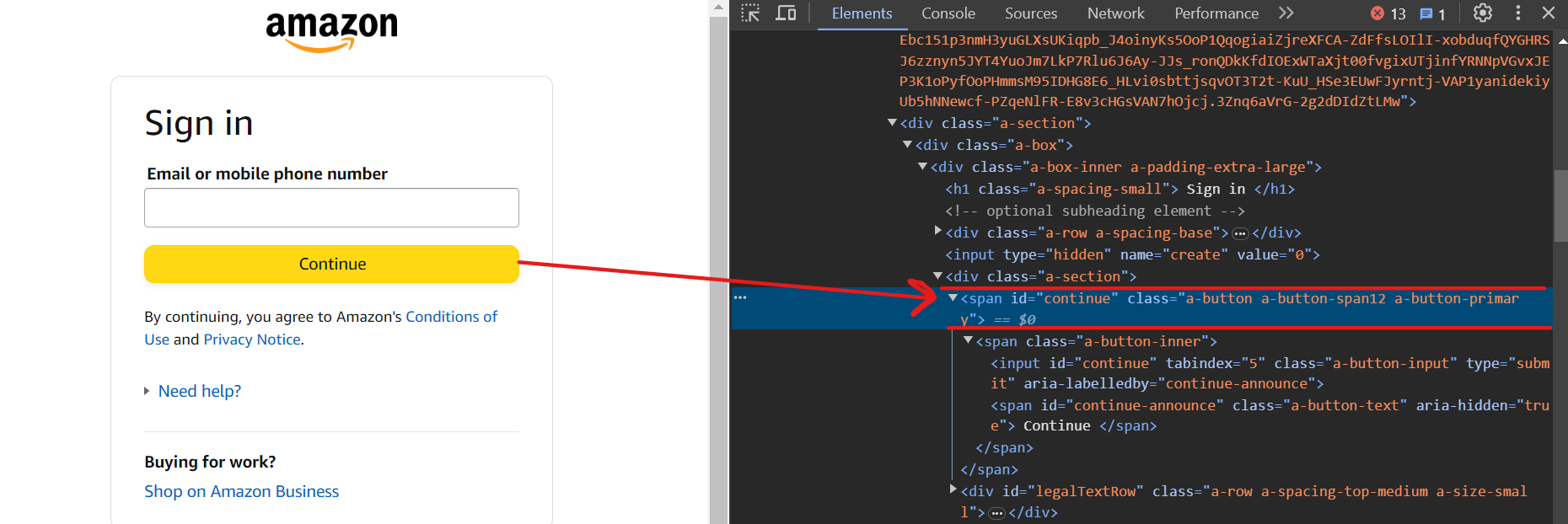
Ahora deberías estar en la siguiente página. Para ingresar la contraseña, utiliza el selector input[name=password].
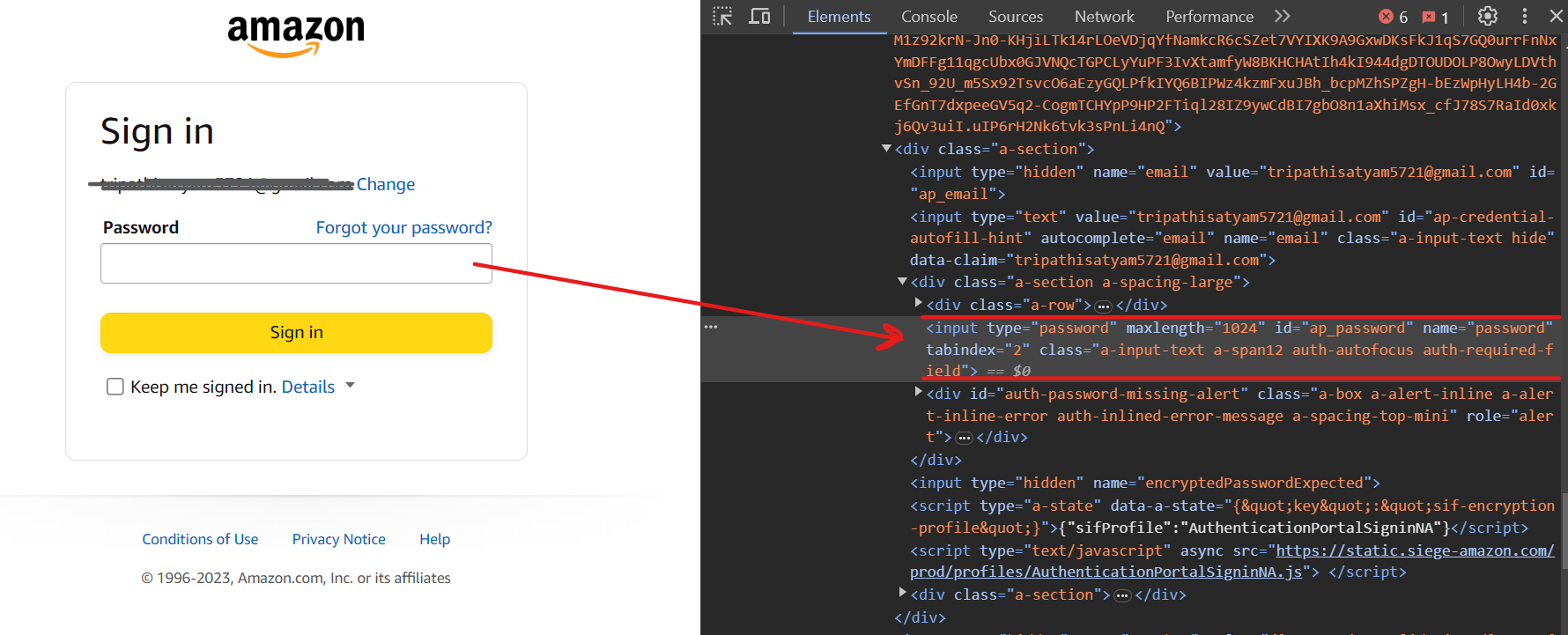
Finalmente, haz clic en el botón Iniciar sesión utilizando el selector input[id=signInSubmit].
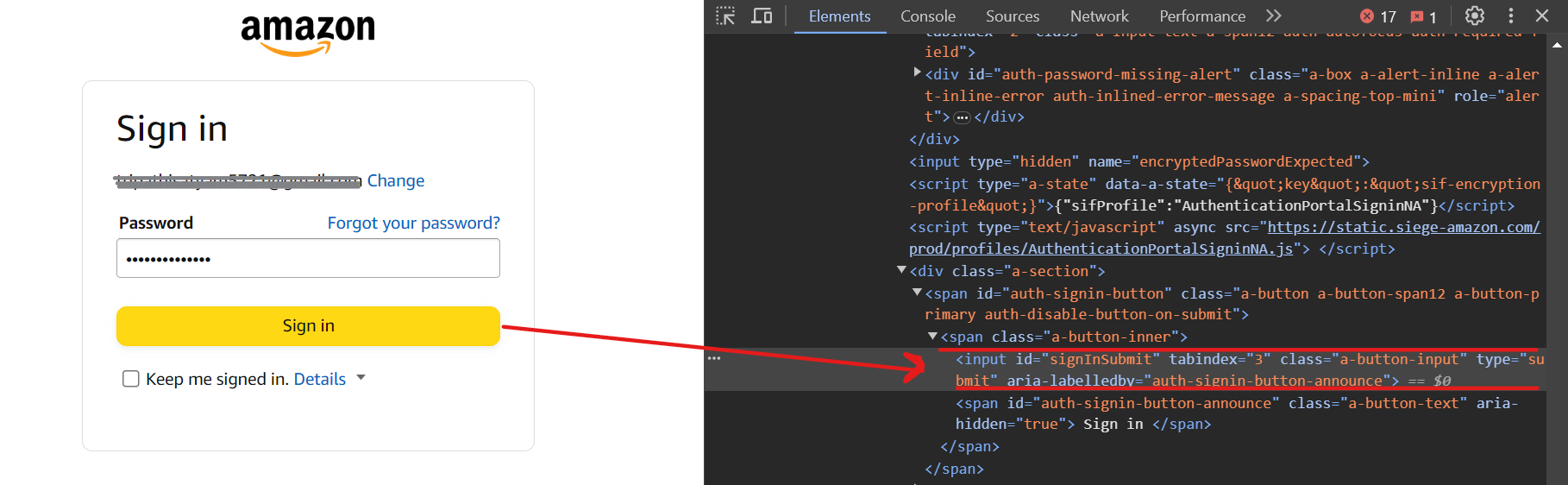
Aquí está el código para el proceso de inicio de sesión:
const selectores = { emailid: 'input[name=email]', password: 'input[name=password]', continuar: 'input[id=continue]', iniciarSesion: 'input[id=signInSubmit]',}; await page.goto(signinURL); await page.waitForSelector(selectores.emailid); await page.type(selectores.emailid, "[email protected]", { delay: 100 }); await page.click(selectores.continuar); await page.waitForSelector(selectores.password); await page.type(selectores.password, "micontraseña", { delay: 100 }); await page.click(selectores.iniciarSesion); await page.waitForNavigation();Estamos siguiendo los mismos pasos que se discutieron anteriormente. Primero, vamos a la URL de inicio de sesión, ingresamos el correo electrónico y hacemos clic en el botón Continuar. Luego ingresamos la contraseña, hacemos clic en el botón Iniciar sesión y esperamos un momento para que se complete el proceso de inicio de sesión.
Después de que se complete el proceso de inicio de sesión, serás redirigido a la página del producto para raspar los comentarios.
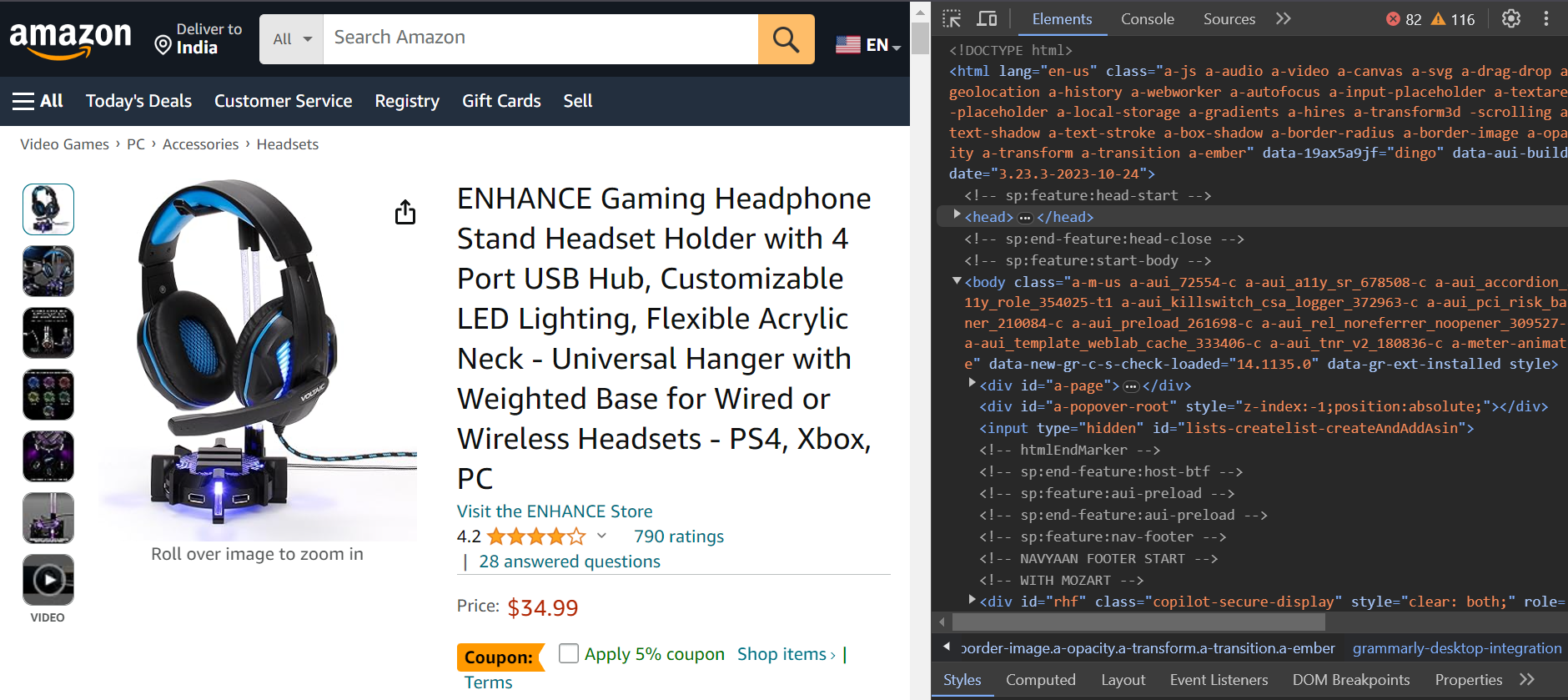
Paso 3: Analizar los datos de los comentarios
Has iniciado sesión con éxito y ahora estás en la página del producto que deseas raspar. Ahora analicemos los datos de los comentarios.
En la página, encontrarás varios comentarios. Estos comentarios se encuentran dentro de un div principal con el ID cm-cr-dp-review-list, que contiene todos los comentarios en la página actual. Si deseas acceder a más comentarios, deberás navegar a la siguiente página utilizando el proceso de paginación.
Este div principal tiene varios divs secundarios, y cada div secundario contiene un comentario. Para extraer los comentarios, puedes utilizar el selector #cm-cr-dp-review-list div.review.
const selectores = { todosLosComentarios: '#cm-cr-dp-review-list div.review', nombreAutor: 'div[data-hook="genome-widget"] span.a-profile-name', tituloComentario: '[data-hook=review-title]>span:not([class])', fechaComentario: 'span[data-hook=review-date]',};Este selector indica que primero vas al elemento con el ID cm-cr-dp-review-list, luego buscas todos los elementos div con el data-hook review.
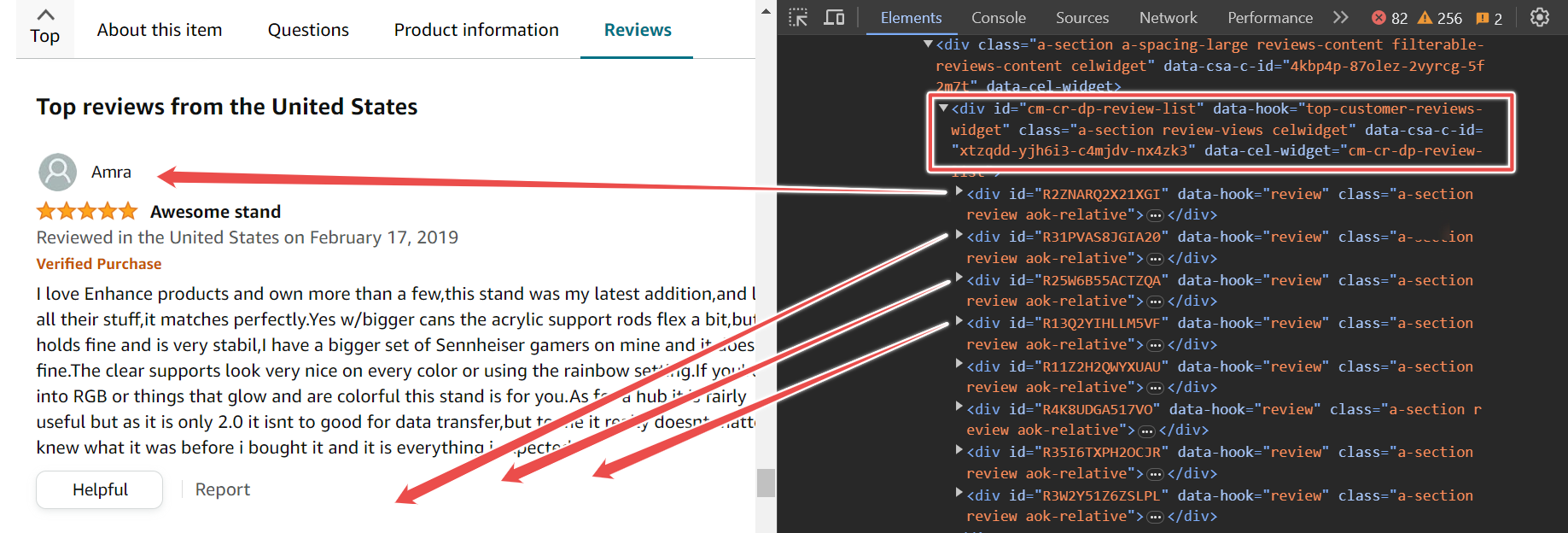
El siguiente fragmento de código muestra que debes ir primero a la URL del producto, esperar a que se cargue el selector y luego raspar todos los comentarios y almacenarlos en la variable elementosComentario.
await page.goto(productURL);await page.waitForSelector(selectores.todosLosComentarios);const elementosComentario = await page.$$(selectores.todosLosComentarios);Ahora, extraigamos el nombre del autor, el título del comentario y la fecha.
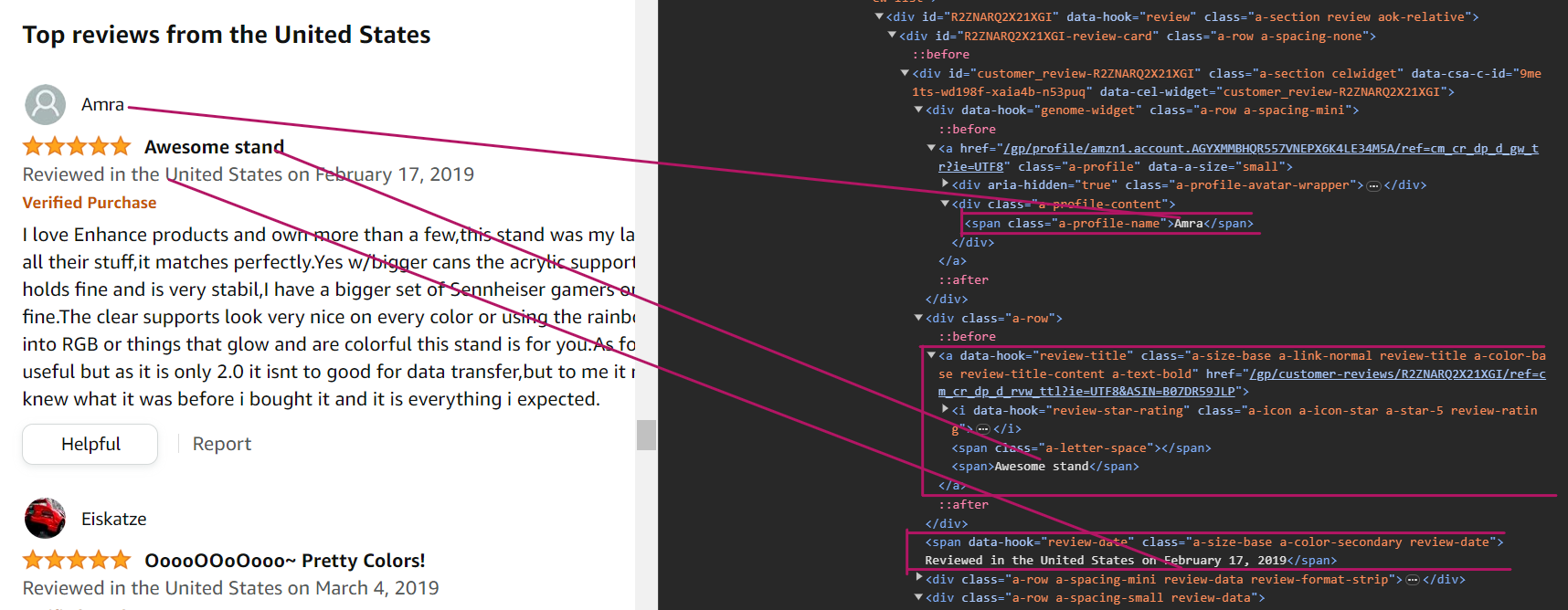
Para analizar el nombre del autor, puedes usar el selector div[data-hook="genome-widget"] span.a-profile-name. Este selector nos indica que primero debemos buscar el elemento div con el atributo data-hook establecido en genome-widget, porque los nombres están dentro de este elemento div. Luego, busca el elemento span con el nombre de clase a-profile-name. Este es el elemento que contiene el nombre del autor.
const author = await reviewElement.$eval(selectors.authorName, (element) => element.textContent);Para analizar el título de la reseña, puedes usar el selector CSS [data-hook="review-title"] > span:not([class]). Este selector nos indica que busquemos el elemento span que es un hijo directo del elemento [data-hook="review-title"] y que no tiene un atributo de clase.
const title = await reviewElement.$eval(selectors.reviewTitle, (element) => element.textContent);Para analizar la fecha, puedes usar el selector CSS span[data-hook="review-date"]. Este selector nos indica que busquemos el elemento span que tiene el atributo data-hook establecido en review-date. Este es el elemento que contiene la fecha de la reseña.
const rawReviewDate = await reviewElement.$eval(selectors.reviewDate, (element) => element.textContent);Ten en cuenta que obtendrás todo el texto, incluida la ubicación, en lugar de solo la fecha completa. Por lo tanto, debes usar un patrón de expresión regular para extraer la fecha del texto.
Luego, combina todos los datos en reviewData y luego agrégalo a la lista final reviewsData.
const datePattern = /(\w+\s\d{1,2},\s\d{4})/; const match = rawReviewDate.match(datePattern); const reviewDate = match ? match[0].replace(',', '') : "Fecha no encontrada"; const reviewData = { author, title, reviewDate, }; reviewsData.push(reviewData); }El proceso anterior se ejecutará hasta que analice todas las reseñas en la página actual. Aquí tienes el fragmento de código para analizar los datos:
for (const reviewElement of reviewElements) { const author = await reviewElement.$eval(selectors.authorName, (element) => element.textContent); const title = await reviewElement.$eval(selectors.reviewTitle, (element) => element.textContent); const rawReviewDate = await reviewElement.$eval(selectors.reviewDate, (element) => element.textContent); const datePattern = /(\w+\s\d{1,2},\s\d{4})/; const match = rawReviewDate.match(datePattern); const reviewDate = match ? match[0].replace(',', '') : "Fecha no encontrada"; const reviewData = { author, title, reviewDate, }; reviewsData.push(reviewData); }¡Genial! Has analizado correctamente los datos relevantes, que ahora están en formato JSON, como se muestra a continuación:
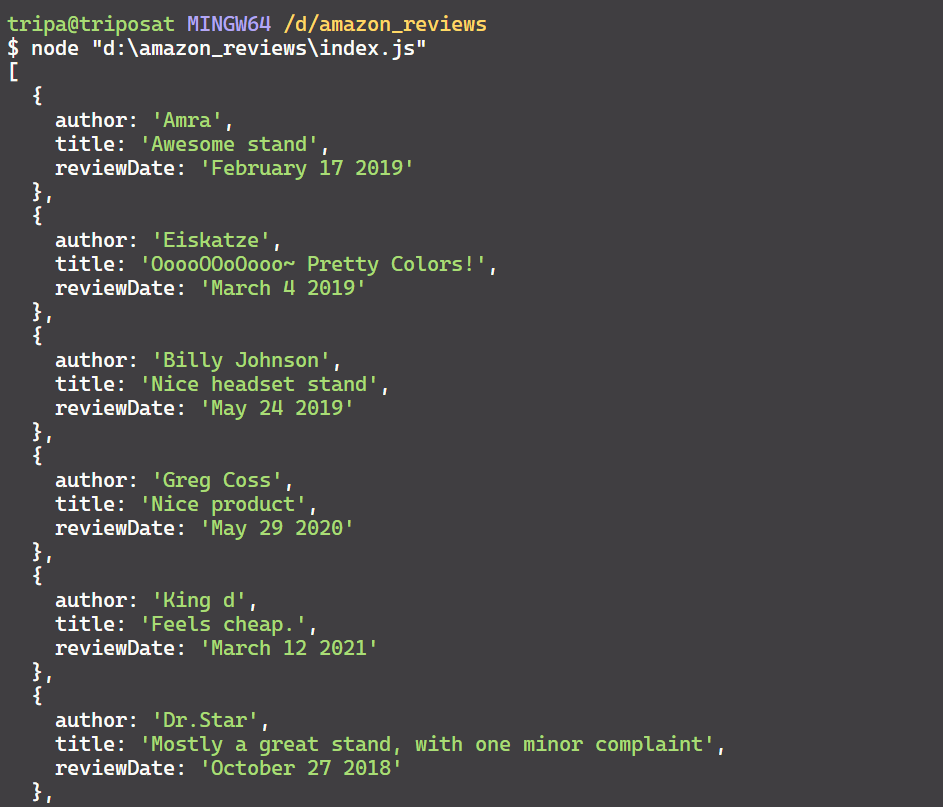
Paso 4: Exportar reseñas a un CSV
Has analizado las reseñas en formato JSON, que es legible para los humanos. Puedes convertir estos datos al formato CSV para que sean más legibles y más fáciles de usar para otros fines.
Hay muchas formas de convertir datos JSON a CSV, pero usaremos un enfoque simple y efectivo. Aquí tienes un sencillo código para convertir JSON a CSV:
let csvContent = "Autor,Título,Fecha\nfor (const review of reviewsData) { const { author, title, reviewDate } = review; csvContent += `${author},"${title}",${reviewDate}\n`; }const csvFileName = "amazon_reviews.csv";await fs.writeFileSync(csvFileName, csvContent, "utf8");Este es el resultado del archivo CSV.

¡Y ahí lo tienes!
Puedes encontrar el código completo subido en GitHub aquí.
Conclusión
En esta guía, aprendiste cómo extraer reseñas de productos de Amazon detrás de un inicio de sesión utilizando Puppeteer. Aprendiste cómo iniciar sesión, analizar datos relevantes y guardarlos en un archivo CSV.
Para practicar más, puedes extraer todas las reseñas de todas las páginas utilizando paginación.



Leave a Reply