Implementación de un Sencillo Recolector de Basura en C#
¿Cómo implementar un recolector de basura simple en C#?
Introducción
La recolección de basura es un proceso en la programación de computadoras y la gestión de memoria donde el sistema identifica automáticamente y libera la memoria que ya no es utilizada por el programa. El propósito principal de la recolección de basura es recuperar la memoria ocupada por objetos o estructuras de datos que ya no son alcanzables o referenciados por el programa, evitando fugas de memoria y mejorando la eficiencia de la utilización de la memoria.
Profundizaremos en los principios fundamentales y las ventajas de este paradigma e implementaremos (en C#) los conceptos teóricos que abordamos, obteniendo información sobre las limitaciones de cada concepto. En última instancia, nuestro objetivo es desarrollar una comprensión completa de cómo funciona la recolección de basura en los lenguajes de programación modernos.
El libro de referencia sobre este tema es El Manual de Recolección de Basura publicado en 2023. Este libro encapsula el conocimiento acumulado por investigadores y desarrolladores en el campo de la gestión automática de memoria en los últimos sesenta años.
¿Qué es exactamente la recolección de basura?
Como se mencionó en la introducción, la recolección de basura es un proceso en la programación de computadoras y la gestión de memoria donde el sistema identifica automáticamente y libera la memoria que ya no es utilizada por el programa.
Conceptos clave de la recolección de basura
-
La recolección de basura automatiza el proceso de liberación de memoria, eliminando la necesidad de administración manual de memoria por parte de los programadores. Esto ayuda a prevenir problemas comunes como fugas de memoria y punteros colgantes (ver más abajo).
-
Los objetos se consideran alcanzables si son referenciados directa o indirectamente por el programa. La recolección de basura identifica y marca los objetos que ya no son alcanzables, haciéndolos elegibles para su eliminación.
-
El recolector de basura identifica y libera la memoria ocupada por objetos no referenciados, devolviéndola al conjunto de memoria disponible para su uso futuro.
-
La recolección de basura puede ser desencadenada por varios eventos, como cuando el sistema tiene poca memoria o cuando se alcanza un umbral específico de memoria asignada.
La recolección de basura es adoptada universalmente por casi todos los lenguajes de programación modernos:
- Java utiliza el recolector de basura de la JVM, que incluye varios algoritmos como el recolector de basura generacional (G1 GC).
- .NET (C#) implementa un recolector de basura que utiliza un enfoque generacional.
La recolección de basura contribuye a la solidez y confiabilidad general de los programas al automatizar la administración de memoria y reducir la probabilidad de errores relacionados con la memoria.
¿Cuál es el problema con la administración manual (explícita) de memoria?
La administración manual de memoria no es inherentemente problemática y todavía se utiliza en ciertos lenguajes de programación prominentes como C++. Sin embargo, muchos están familiarizados con casos de errores críticos atribuibles a fugas de memoria. Por esta razón, relativamente temprano en la historia de la ciencia de la computación (con la primera técnica datando de la década de 1950), se estudiaron métodos para administrar automáticamente la memoria.
La administración manual de memoria de hecho introduce varios desafíos y posibles problemas:
-
La falta de liberación adecuada de memoria puede provocar fugas de memoria. Las fugas de memoria ocurren cuando un programa asigna memoria pero no la libera, lo que resulta en una reducción gradual de la memoria disponible con el tiempo.
-
El manejo incorrecto de los punteros puede resultar en punteros colgantes, que apuntan a ubicaciones de memoria que han sido liberadas. Acceder a esos punteros puede provocar un comportamiento indefinido y bloqueos de la aplicación.
-
La manipulación incorrecta de la memoria, como escribir más allá de los límites de la memoria asignada, puede causar corrupción de memoria. La corrupción de memoria puede provocar un comportamiento inesperado, bloqueos o vulnerabilidades de seguridad.
-
La administración manual de memoria aumenta la complejidad del código, lo que hace que los programas sean más propensos a errores y más difíciles de mantener. Los desarrolladores deben rastrear y administrar cuidadosamente las asignaciones y liberaciones de memoria en todo el código.
-
La administración manual de memoria puede contribuir a la fragmentación de la memoria, donde la memoria libre está dispersa en bloques pequeños y no contiguos. Esta fragmentación puede llevar a una utilización ineficiente de la memoria con el tiempo.
-
Pueden producirse operaciones de asignación y liberación incompatibles, lo que lleva a errores como la liberación doble de memoria o fugas de memoria. Estos errores son difíciles de identificar y depurar.
-
La administración explícita de memoria puede requerir código adicional para la asignación y liberación, lo que afecta el rendimiento del programa. Las operaciones de asignación y liberación de memoria pueden convertirse en cuellos de botella en aplicaciones críticas en términos de rendimiento.
-
La administración manual de memoria carece de características de seguridad presentes en los sistemas de administración automática de memoria. Los desarrolladores deben manejar cuidadosamente las operaciones relacionadas con la memoria, lo que hace que los programas sean más propensos a errores.
La administración automática de memoria aborda estos problemas automatizando el proceso de asignación y desasignación de memoria, reduciendo la carga sobre los desarrolladores y minimizando la probabilidad de errores relacionados con la memoria.
Una visión más completa de los beneficios de la recolección de basura y las desventajas de la gestión explícita de la memoria se proporciona en el Manual del Recolector de Basura.
¿Qué son las Pilas, los Montones y Más?
Cuando se habla de recolección de basura, los términos pila y montón se mencionan con frecuencia hasta el punto de que pueden crear la impresión de que son estructuras de datos inherentes incrustadas en el sistema operativo y, por lo tanto, deben adoptarse universalmente sin cuestionamiento. Sin embargo, la realidad es que el montón y las pilas son solo detalles de implementación. En esta sección, nuestro objetivo es elucidar y aclarar todos estos conceptos.
En el Principio Era la Palabra
Un programa es esencialmente un texto que comprende instrucciones que una computadora necesita comprender. La responsabilidad del compilador es emprender la traducción de estas instrucciones de alto nivel en código ejecutable.
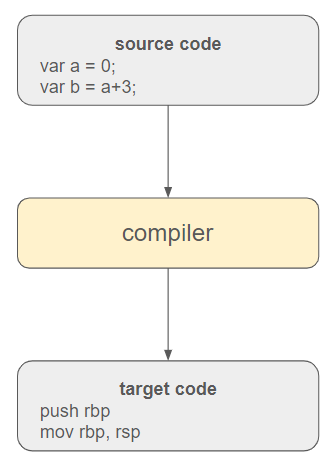
En los lenguajes de programación contemporáneos, a menudo se intercala un motor de ejecución virtual entre el código fuente y el sistema operativo. Además, el código fuente se traduce inicialmente a un lenguaje intermedio para mejorar la portabilidad y la adaptabilidad a diferentes entornos.
Este motor de ejecución engloba el recolector de basura y otras técnicas (como la comprobación de tipos, la gestión de excepciones, etc.) para administrar el programa. La traducción final a código objetivo la realiza el compilador de tiempo de ejecución (JIT).
Enfocado en el Recolector de Basura
Indudablemente, el recolector de basura destaca como uno de los componentes más críticos del motor de ejecución. En este contexto, nuestro enfoque se centrará en describir cómo se organiza la memoria para facilitar una gestión efectiva.
Un programa solo se vuelve valioso cuando genera un resultado y, inevitablemente, necesita declarar variables y asignar memoria para almacenar información en algún momento.
- El motor de ejecución puede anticipar el espacio que requiere de antemano, como al tratar con tipos simples como enteros. Por el contrario, ciertos tipos de datos, incluidas las clases personalizadas o los tipos incorporados como cadenas o matrices de objetos, no permiten una inferencia tan directa.
- El compilador solo puede determinar en tiempo de ejecución la ubicación específica para almacenar variables y reservar memoria en ese momento (asignación dinámica). Si el compilador puede determinar el ciclo de vida de la variable, especialmente si es local a un procedimiento, se vuelve más fácil comprender cuándo no será necesario (es decir, cuándo se puede realizar la desasignación). Por el contrario, los datos pueden persistir más allá de la llamada a una función o subrutina y perdurar indefinidamente.
La disparidad entre el ciclo de vida de una variable y el espacio conocido de antemano que se requiere hace necesaria la distinción entre dos áreas de memoria. Aunque esta diferenciación no es obligatoria, se ha aceptado e implementado universalmente. Un lenguaje de programación que elija no adoptar esta abstracción puede enfrentar el riesgo de caer en la obsolescencia, pero es esencial reconocer que existen esquemas alternativos concebibles. Además, es crucial tener en cuenta que esta perspectiva solo es válida dentro del contexto del motor de ejecución. Desde el punto de vista del sistema operativo, todo se reduce eventualmente a fragmentos de memoria asignados en alguna parte.
Conclusión
- Cuando el motor de ejecución puede anticipar el ciclo de vida de una variable e inferir el espacio requerido, lo asigna en un área de memoria llamada la pila.
- En otros casos, donde no se puede decidir definitivamente el ciclo de vida o el espacio requerido no está claro, el motor de ejecución asigna variables en áreas de memoria denominadas el montón.
Aviso legal: Esta descripción proporciona solo una descripción básica de lo que son las pilas y los montones en varios lenguajes de programación, y los puristas pueden encontrarla simplificada en exceso. De ninguna manera es una definición oficial, ya que podría haber diversas implementaciones e interpretaciones de estas abstracciones. La idea principal es la necesidad de delinear dos áreas de memoria a nivel del motor de ejecución para facilitar una gestión eficiente de la memoria.
Suficiente Teoría, ¡Code Por Favor!
Deberíamos imaginar un escenario en el que un programa se escribe inicialmente en código fuente y luego se compila en una representación intermedia, que se manifiesta como una lista secuencial de instrucciones. Supondremos que el compilador de IL ha generado esta lista de instrucciones. A continuación se muestra un ejemplo de tal lista.
thread1;CREATE_THREAD; thread1;PUSH_ON_STACK;Jubilant thread2;CREATE_THREAD; thread1;PUSH_ON_STACK;Radiant thread1;POP_FROM_STACK...
Cada instrucción consta de tres componentes. El primero indica qué hilo se ve afectado por la instrucción, el segundo describe la operación que se va a realizar y el tercero (opcional) proporciona un valor para complementar la operación. En el ejemplo proporcionado, inicialmente se instruye al compilador para crear un hilo llamado thread1 y luego colocar una variable llamada Jubilant en la pila de este hilo. La tercera instrucción llama a la creación de otro hilo llamado thread2 y así sucesivamente. La quinta instrucción intenta desapilar la pila de thread1.
Esta lista de instrucciones se puede imaginar como una representación intermedia (IR), como se ilustra en “Compilers: Principles, Techniques and Tools”.
Nuestra tarea actual es implementar un motor de ejecución (tiempo de ejecución) capaz de manejar estas instrucciones, con un enfoque particular en la asignación y desasignación de memoria.
Implementando el Tiempo de Ejecución
Sin más demora, aquí está cómo se implementa el tiempo de ejecución en nuestro código.
public class Runtime{ private List<Instruction> _instructions; private Collectors.Interfaces.GarbageCollector _collector; public Runtime(List<Instruction> instructions, string collectorStrategy) { _instructions = instructions; _collector = GetCollector(collectorStrategy); } #region Public Methods public void Run() { foreach (var instruction in _instructions) { _collector.ExecuteInstruction(instruction); _collector.PrintMemory(); } } #endregion}
El motor de ejecución posee la lista de instrucciones a ejecutar y un recolector de basura (descrito a continuación) que se utilizará durante la desasignación de memoria. También incluye un método Run que es llamado por el hilo principal.
public class Program{ static void Main(string[] args) { var instructions = new List<Instruction>(); var contents = File.ReadAllLines(AppContext.BaseDirectory + "/instructions.txt"); foreach (var line in contents) { var c = line.Split(';'); var instruction = new Instruction(c[0], c[1], c[2]); instructions.Add(instruction); } var runtime = new Runtime(instructions, "MARK_AND_COMPACT"); runtime.Run(); }}
La clase Runtime también requiere una estrategia de recolección de memoria para aplicar. Como exploraremos más adelante, existen varias posibilidades para la recolección de memoria, y diseñar un recolector de basura efectivo es realmente un arte sutil.
Definiendo la Interfaz GarbageCollector
La clase Runtime requiere una instancia de GarbageCollection para operar. Esta instancia implementa la clase abstracta GarbageCollection, cuyos métodos se detallan a continuación:
public abstract class GarbageCollector{ public abstract void ExecuteInstruction(Instruction instruction); public abstract int Allocate(string field); public abstract void Collect(); public abstract void PrintMemory(); }
En esencia, la clase GarbageCollector presentada aquí sirve como un orquestador para ejecutar la lista de instrucciones y gestionar la asignación y recolección de memoria. En implementaciones del mundo real, estas abstracciones típicamente se mantendrían separadas, pero con el objetivo de simplificar la representación, aquí se han unificado.
El método PrintMemory es simplemente una función de ayuda diseñada para visualizar el contenido del montón durante la depuración.
Definiendo un Hilo
Un hilo se refiere a la unidad más pequeña de ejecución dentro de un proceso. Un proceso es un programa independiente que se ejecuta en su propio espacio de memoria y, dentro de un proceso, múltiples hilos pueden existir. Cada hilo comparte los mismos recursos, como la memoria, con otros hilos en el mismo proceso.
- Los hilos permiten la ejecución concurrente de tareas, lo que permite realizar múltiples operaciones simultáneamente. Operan de forma independiente, con su propio contador de programa, registros y pila, pero comparten el mismo espacio de memoria. Los hilos dentro del mismo proceso pueden comunicarse y sincronizarse entre sí.
- Los hilos se utilizan ampliamente en el desarrollo de software moderno para mejorar el rendimiento, la capacidad de respuesta y la utilización de recursos en aplicaciones que van desde software de escritorio hasta aplicaciones de servidor y sistemas distribuidos.
public class RuntimeThread { private Collectors.Interfaces.GarbageCollector _collector; private Stack<RuntimeStackItem> _stack; private Dictionary<int, RuntimeStackItem> _roots; private int _stackSize; private int _index; public string Name { get; set; } public RuntimeThread(Collectors.Interfaces.GarbageCollector collector, int stackSize, string name) { _collector = collector; _stack = new Stack<RuntimeStackItem>(stackSize); _roots = new Dictionary<int, RuntimeStackItem>(); _stackSize = stackSize; _index = 0; Name = name; } public Dictionary<int, RuntimeStackItem> Roots => _roots; public void PushInstruction(string value) { _index++; if (_index > _stackSize) throw new StackOverflowException(); var address = _collector.Allocate(value); var stackItem = new RuntimeStackItem(address); _stack.Push(stackItem); _roots.Add(address, stackItem); } public void PopInstruction() { _index--; var item = _stack.Pop(); _roots.Remove(item.StartIndexInTheHeap); } }
Un hilo se caracteriza por un nombre y ejecuta su propia lista de instrucciones. El punto crucial es que los hilos comparten la misma memoria. Esto se traduce en que en un programa puede haber varios hilos y, en consecuencia, varias pilas, pero generalmente hay un montón compartido entre todos los hilos.
En el ejemplo proporcionado, cuando un hilo ejecuta una instrucción, se coloca en su pila y cualquier referencia potencial al montón se mantiene en un diccionario interno. Este mecanismo asegura que cada hilo mantenga su propia pila mientras las referencias al montón compartido se rastrean para administrar la asignación y desasignación de memoria de manera efectiva.
Definir las Pilas y el Montón
Como se mencionó anteriormente, las pilas y el montón son detalles de implementación, por lo que su código se pospone a las clases concretas de GarbageCollector. Aún así, podría ser informativo proporcionar una breve descripción de ellos porque, como observamos, estos conceptos son universalmente adoptados.
Implementando la Pila
En C#, ya existe una estructura de datos para las pilas. Para simplificar, la usaremos, especialmente porque se adapta bien a nuestros requisitos.
Empujaremos instancias de una clase RuntimeStackItem a esta pila. RuntimeStackItem solo contiene una referencia a una dirección en el montón.
public class RuntimeStackItem{ public int StartIndexInTheHeap { get; set; } public RuntimeStackItem(int startIndexInTheHeap) { StartIndexInTheHeap = startIndexInTheHeap; }}
Implementando el Montón
Un montón debe representar un área de memoria y simplemente modelaremos cada celda de memoria con una clase char. Con esta abstracción, un montón no es más que una lista de celdas que se pueden asignar. También incluye código adicional, como punteros, para administrar qué celdas están ocupadas o se pueden reclamar.
public class RuntimeHeap{ public RuntimeHeap(int size) { Size = size; Cells = new RuntimeHeapCell[size]; Pointers = new List<RuntimeHeapPointer>(); for (var i = 0; i < size; i++) { Cells[i] = new RuntimeHeapCell(); } } #region Properties public int Size { get; set; } public RuntimeHeapCell[] Cells { get; set; } public List<RuntimeHeapPointer> Pointers { get; set; } #endregion}
Nuestra tarea ahora es definir clases concretas de GarbageCollection para observar un recolector de basura en acción.
Implementando el Algoritmo de Marcar y Limpiar
Para esta estrategia y las siguientes, asignaremos un montón de 64 caracteres y consideraremos que es imposible reclamar espacio adicional del sistema operativo. En un escenario del mundo real, el recolector de basura típicamente tiene la capacidad de solicitar nueva memoria, pero con fines ilustrativos, imponemos esta limitación. Es importante destacar que esta limitación no dificulta ni resta comprensión en general.
Implementando el Método ExecuteInstruction
Este método es casi el mismo para todas las estrategias. Procesa una instrucción a la vez, empujando o sacando variables de la pila.
public override void ExecuteInstruction(Instruction instruction){ if (instruction.Operation == "CREATE_THREAD") { AddThread(instruction.Name); return; } var thread = _threads.FirstOrDefault(x => x.Name == instruction.Name); if (thread == null) return; if (instruction.Operation == "PUSH_ON_STACK") { thread.PushInstruction(instruction.Value); } if (instruction.Operation == "POP_FROM_STACK") { thread.PopInstruction(); }}
Implementando el Método Allocate
Si no hay suficiente memoria, el recolector de basura intenta reclamar memoria y luego vuelve a intentar el proceso de asignación. Si aún no hay suficiente espacio, se lanza una excepción.
public override int Allocate(string field){ var r = AllocateHeap(field); if (r == -1) { Collect(); r = AllocateHeap(field); } if (r == -1) throw new InsufficientMemoryException(); return r;}private int AllocateHeap(string field){ var size = _heap.Size; var cells = field.ToArray(); var requiredSize = cells.Length; // Necesitamos encontrar un espacio contiguo de requiredSize chars. var begin = 0; while (begin < size) { var c = _heap.Cells[begin]; if (c.Cell != '\0') { begin++; continue; } // No continuar si no hay suficiente espacio. if ((size - begin) < requiredSize) return -1; // c = 0 => Esta celda está libre. var subCells = _heap.Cells.Skip(begin).Take(requiredSize).ToArray(); if (subCells.All(x => x.Cell == '\0')) { for (var i = begin; i < begin + requiredSize; i++) { _heap.Cells[i].Cell = cells[i - begin]; } var pointer = new RuntimeHeapPointer(begin, requiredSize); _heap.Pointers.Add(pointer); return begin; } begin++; } return -1;}
Importante: El proceso de asignación siempre busca espacio libre contiguo (línea 23 del código fuente de arriba). Por ejemplo, si tiene que asignar 8 celdas, debe localizar 8 celdas libres contiguas. Esta observación será crucial en las secciones siguientes (ver abajo).
¿Qué es el algoritmo de marcado y barrido?
El algoritmo de marcado y barrido consta de dos fases principales: el marcado y el barrido.
- En la fase de marcado, el algoritmo recorre todos los objetos en el montón, comenzando desde las raíces (normalmente variables globales u objetos referenciados directamente por el programa). Marca cada objeto visitado como “alcanzable” o “vivo” estableciendo una bandera o atributo específico. Los objetos no marcados durante esta exploración se consideran inalcanzables y son potenciales candidatos para la desasignación.
- En la fase de barrido, el algoritmo recorre todo el montón, identificando y desasignando la memoria ocupada por objetos no marcados (inalcanzables). La memoria ocupada por objetos marcados (alcanzables) se conserva. Después del barrido, el montón vuelve a considerarse un bloque contiguo de memoria libre, listo para nuevas asignaciones.
El algoritmo de marcado y barrido es conocido por su simplicidad y eficacia en la identificación y recuperación de memoria que ya no se utiliza. Sin embargo, tiene algunas desventajas, como veremos a continuación.
En resumen, un objeto se considera muerto (y por lo tanto recuperable) hasta que demuestre lo contrario al ser alcanzable desde algún lugar del programa.
public override void Collect(){ MarkFromRoots(); Sweep();}
Implementando la fase de marcado
El algoritmo de marcado y barrido debe comenzar su exploración desde las raíces. ¿Qué constituye estas raíces? Normalmente, incluyen variables globales o referencias contenidas en el marco de cada pila. En nuestro ejemplo simplificado, definiremos las raíces como exclusivamente los objetos referenciados en la pila.
private void MarkFromRoots(){ var pointers = _heap.Pointers; foreach (var root in _threads.SelectMany(x => x.Roots)) { var startIndexInTheHeap = root.Value.StartIndexInTheHeap; var pointer = pointers.FirstOrDefault(x => x.StartCellIndex == startIndexInTheHeap); if (pointer == null) return; pointer.SetMarked(true); }}
Al final del procedimiento, los objetos vivos han sido marcados, mientras que los objetos muertos no lo han sido.
Implementando la fase de barrido
La fase de barrido recorre todo el montón y recupera memoria de los objetos que no están marcados.
private void Sweep(){ var cells = _heap.Cells; var pointers = _heap.Pointers; foreach (var pointer in pointers.Where(x => !x.IsMarked)) { var address = pointer.StartCellIndex; for (var i = address; i < address + pointer.AllocationSize; i++) { cells[i].Cell = '\0'; } } var list = new List<RuntimeHeapPointer>(); foreach (var pointer in pointers.Where(x => x.IsMarked)) { pointer.SetMarked(false); list.Add(pointer); } pointers = list;}
En este procedimiento, no olvidamos reinicializar los punteros marcados y establecerlos como no marcados para asegurarnos de que la siguiente recolección funcione nuevamente en un estado limpio.
Ejecutando el programa
Ejecutaremos el programa con dos listas de instrucciones. La primera es idéntica a la del artículo anterior. La segunda destacará un fenómeno específico de este algoritmo conocido como fragmentación.
Con el mismo conjunto de instrucciones que antes, observamos que el programa se ejecuta hasta el final sin levantar ninguna excepción. La palabra “Cascade” se asignó correctamente porque el recolector de basura logró recuperar suficiente memoria.
Este algoritmo garantiza que la memoria se recupere correctamente cuando sea necesario. Sin embargo, en el siguiente ejemplo, observaremos un efecto no deseado cuando modificamos ligeramente nuestras instrucciones e intentamos asignar memoria para una palabra larga (16 letras).
...thread1;PUSH_ON_STACK;Enigmaticthread2;POP_FROM_STACK;thread1;PUSH_ON_STACK;Cascadethread2;POP_FROM_STACK;thread2;PUSH_ON_STACK;GarbageCollector <= palabras de 16 letras
Curiosamente, se levanta una excepción a pesar de que parece haber suficiente memoria libre en el montón.
Hay 19 celdas libres en el montón y estamos intentando asignar 16 celdas, ¿entonces por qué el recolector de basura no logra realizar la tarea?
En realidad, el recolector de basura intenta localizar 16 celdas libres CONTIGUAS, pero parece que el montón no las posee. Aunque tiene más de 16 celdas libres, no son contiguas, lo que hace que la asignación sea imposible. Este fenómeno se conoce como fragmentación y tiene algunos efectos indeseables.
En general, la fragmentación del montón se refiere a una situación en la que la memoria libre en un montón está dispersa en bloques no contiguos, lo que dificulta la asignación de un fragmento grande y contiguo de memoria, incluso si el espacio libre total es suficiente. Si bien la cantidad total de memoria libre puede ser considerable, la naturaleza dispersa de estos bloques obstaculiza la asignación de porciones grandes y contiguas de memoria.
En el contexto del algoritmo de marcado y barrido, la necesidad de bloques de memoria contiguos para ciertas asignaciones puede ser obstaculizada por la disposición dispersa de las celdas de memoria libre en el montón. Como consecuencia, incluso si el espacio libre total es adecuado, la incapacidad para encontrar un segmento lo suficientemente grande y contiguo puede llevar a fallas en la asignación.
Por lo tanto, es crucial abordar la fragmentación del montón para optimizar el uso de memoria y mejorar el rendimiento de un recolector de basura.
Puedes encontrar la continuación de este artículo aquí.
Historia
- 18 de noviembre de 2023: Versión inicial








Leave a Reply