Empezar con Quarkus y JPAStreamer
Comenzar con Quarkus y JPAStreamer
Nota: Este artículo es de Julia Gustafsson.
En el mundo del desarrollo de software, la innovación a menudo llega en forma de herramientas poderosas que transforman la forma en que construimos aplicaciones: ingresa Quarkus, una plataforma de desarrollo que está remodelando el panorama de Java.
Si eres nuevo en el Quarkiverso, este tutorial es una excelente manera de comenzar a explorar cómo puede mejorar radicalmente tu experiencia de desarrollo en Java. Te mostraré cómo armar rápidamente una aplicación REST en la plataforma Quarkus, aprovechando el poder de JPAStreamer, una extensión de Hibernate para manejar las interacciones con la base de datos con la elegancia del API Stream de Java.
Al final de este recorrido, tendrás los conocimientos necesarios para optimizar sin problemas tus futuras aplicaciones Java para implementación en la nube. Además, no me sorprendería si descubres que Java es mucho más agradable con recargas de código en vivo y pruebas continuas.
Si prefieres una guía visual, hay una versión en video de este tutorial disponible en el canal de YouTube de freeCodeCamp.org (aproximadamente 1 hora).
1. Qué Construiremos
Este tutorial sirve como una guía completa para construir una aplicación Quarkus robusta. Cubriremos todos los aspectos esenciales, desde configurar tu entorno de desarrollo y establecer una conexión a la base de datos, hasta definir puntos finales REST, dominar Java Streams con JPAStreamer para consultas potentes, realizar pruebas continuas sin esfuerzo y lograr compilación nativa. El resultado final es una aplicación REST liviana que proporciona información de una muestra de una película en fracciones de segundo después de un inicio en frío, sentando las bases para tus futuros proyectos Quarkus.
En la superficie, esto parece ser otra guía sobre cómo desarrollar una aplicación, pero en la práctica, también es un vistazo a cómo se siente desarrollar con Quarkus.
Durante el desarrollo, te familiarizarás con los siguientes temas:
- Configuración de un proyecto Quarkus
- Conexión a una instancia de MySQL en Docker
- Uso del modo de desarrollo Quarkus
- Expresión de consultas como Java Streams con JPAStreamer
- Realización de pruebas continuas
- Compilación de la aplicación de forma nativa para tiempos de inicio rápidos y consumo mínimo de memoria
1.1 ¿Qué hace que Quarkus sea especial?
Quarkus suele describirse como un marco moderno para aplicaciones Java y Kotlin, orientado a la nube y de vanguardia. Su misión es abordar desafíos en Java que han persistido durante mucho tiempo, como los tiempos prolongados de inicio, el alto consumo de memoria y una experiencia de desarrollo bastante lenta.
Logra este objetivo con dos características de diseño ingeniosas: un proceso de compilación mejorado que realiza gran parte del trabajo pesado durante la compilación en lugar de durante el inicio de la aplicación, y como extensión de eso, un modo de desarrollo que te permite ejecutar tu aplicación e incorporar cualquier actualización de código al vuelo.
Cuatro años después de su lanzamiento inicial, Quarkus cuenta con una amplia variedad de extensiones, asegurando una integración perfecta con todas las principales bibliotecas de Java como Hibernate, Spring y JUnit.
1.2 ¿Qué es JPAStreamer?
JPAStreamer es una biblioteca liviana diseñada para simplificar el acceso a bases de datos en aplicaciones Java que utilizan la API de Persistencia de Java (JPA). Su poder reside en sus consultas expresivas y seguras en cuanto al tipo de datos que ayudan a mejorar la precisión y la productividad en la programación.
JPAStreamer optimiza el rendimiento al traducir tuberías en consultas lenguaje de consulta de Hibernate (HQL). A diferencia de usar getResultStream() en Hibernate, que materializa todas las entidades, JPAStreamer asegura que solo se obtengan las entidades relevantes, similar a utilizar SQL directamente.
Imagina obtener 10 películas de una base de datos donde cada título comienza con “A” y dura al menos 1 hora. Con JPAStreamer, la consulta es tan simple como:
List<Film> films = jpaStreamer.stream(Film.class) .filter(Film$.title.startsWith("A") .and(Film$.length.greaterThan(60)) .limit(10) .collect(Collectors.toList());2. Prerrequisitos
Antes de poner manos a la obra y comenzar a codificar, es importante asegurarse de tener todo lo necesario en su lugar. Aunque el tutorial cubre todos los detalles necesarios para obtener una aplicación completamente funcional, se asume que:
- Estás familiarizado con Java básico
- Conoces el API Stream de Java
- Te sientes cómodo con las interacciones con bases de datos utilizando JPA/Hibernate
Si planeas seguir en tu máquina local, asegúrate de que tu entorno de desarrollo cumpla con los siguientes requisitos:
- Java 11 o superior
- Un IDE de tu elección (la guía utiliza IntelliJ)
- Maven (o Gradle)
- Quarkus CLI
- Docker y Docker CLI (o tu propia base de datos)
- Opcional: instalación de GraalVM
3. Configuración del Proyecto
Una vez que hayas verificado la lista de requisitos previos, es hora de crear un nuevo proyecto Quarkus. Hay varias formas de hacer esto, pero para simplificar, utilizaré el configurador de proyectos Quarkus que se encuentra en code.quarkus.io/. Esta herramienta te permite armar rápidamente un archivo de compilación completo con las dependencias necesarias.
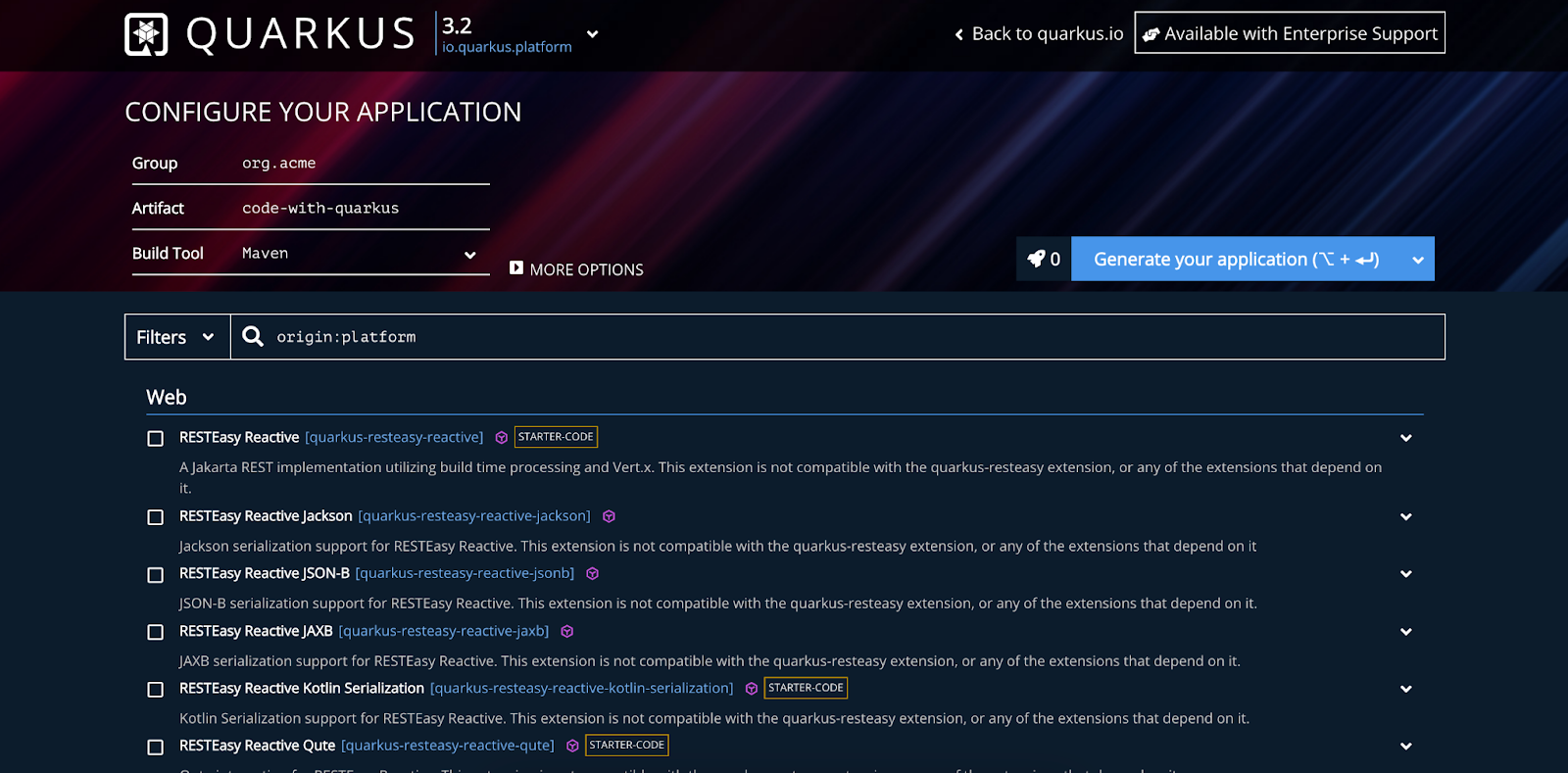
Comienza seleccionando una versión de Quarkus en la parte superior de la página. Recomiendo utilizar la versión más reciente o seleccionar una versión LTS, por ejemplo, 3.2 (la más reciente al momento de escribir). Después de nombrar adecuadamente tu proyecto, selecciona las siguientes dependencias:
- Hibernate ORM con Panache: Maneja las interacciones con la base de datos
- JPAStreamer: Extensión de Hibernate para consultas intuitivas y seguras en cuanto a tipos
- SmallRye OpenAPI: Permite utilizar Swagger UI para enviar solicitudes de prueba
- RESTEasy Reactive Jackson: Facilita la configuración sencilla de endpoints REST
- JDBC Driver – MySQL: Nuestro controlador de base de datos
Luego simplemente presiona “Generar tu aplicación” para descargar un archivo ZIP del proyecto. Puedes descargar un inicio de Quarkus con mis configuraciones exactas a través de este enlace.
A partir de aquí, abre el proyecto en tu IDE favorito. Al echar un vistazo rápido a la estructura del proyecto, notarás que Quarkus ha organizado el proyecto en una estructura familiar de Maven, con un archivo pom.xml para las dependencias y la configuración del proyecto.
quarkus-tutorial |- src | |- main | | |- java | | |- resources |- srcSi revisas el archivo pom.xml, encontrarás las dependencias seleccionadas. También observa que JUnit se agrega automáticamente para la fase de prueba continua posterior.
4. Configuración de la Base de Datos
A medida que me sumerjo en el mundo de las nuevas tecnologías, a menudo incluyo la base de datos de muestra Sakila de Oracle en mi entorno de desarrollo, ya que está disponible fácilmente como una imagen Docker. Este proyecto no es una excepción.
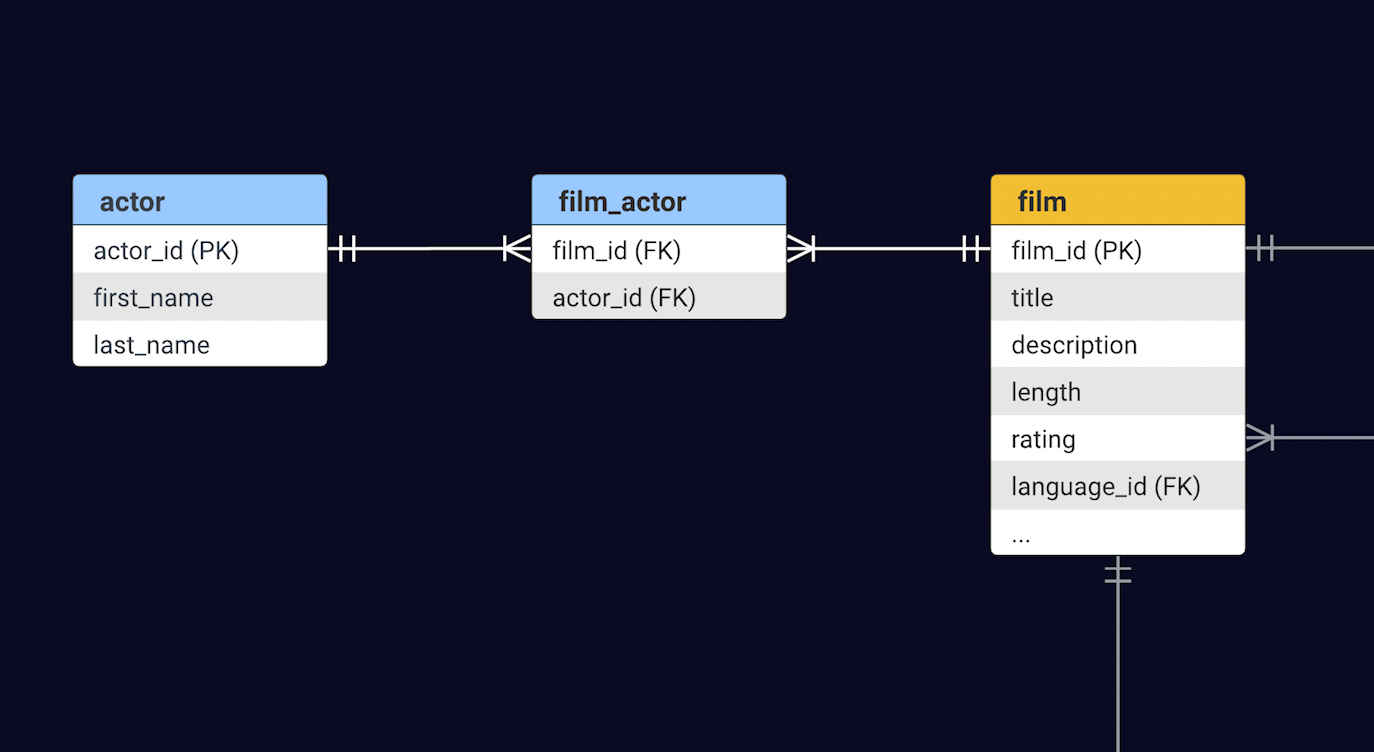
Sakila modela una antigua tienda de alquiler de videos, del tipo en el que esperabas ansiosamente una película en cinta o DVD. Naturalmente, el núcleo de esta base de datos se centra en la tabla Film, complementada por varias tablas de soporte, como Inventory, Customer y Payment. Para esta demostración, nos enfocaremos en proporcionar información sobre películas y los actores que protagonizan esas películas. Las tablas Film y Actor comparten una relación de muchos a muchos: una película puede contar con muchos actores y, a su vez, un actor puede protagonizar numerosas películas.
Para descargar e iniciar la base de datos en el puerto 3306, utiliza la Docker CLI.
docker run --platform linux/amd64 -d --publish 3306:3306 --name sakila restsql/mysql-sakila
La bandera --platform le indica a Docker que acepte la imagen de Sakila Linux AMD64 independientemente de la plataforma local. En mi experiencia, funciona bien en otras plataformas.
Al ejecutar este comando, deberías observar que la imagen se descarga y se inicia.
5. Configuración de Hibernate
Para facilitar las interacciones con la base de datos a través de Hibernate, se requiere un poco de configuración. Si bien Hibernate en el dominio de Quarkus se comporta de manera similar a Hibernate estándar en cualquier aplicación Java, configurarás Hibernate en el archivo application.configuration. En segundo lugar, generaremos el esqueleto JPA con la ayuda de IntelliJ.
5.1 Configurando Hibernate
El archivo application.configuration se encuentra en la carpeta /resources de la plantilla del proyecto que descargaste inicialmente. Este archivo actúa como un centro que atiende varias dependencias y extensiones potenciales de Quarkus. Esto significa que nuestra configuración de base de datos no será específica de Hibernate; cualquier framework que necesite interacción con la base de datos puede hacer uso de esta configuración.
No obstante, la configuración es similar a la configuración regular de la base de datos de Hibernate. Suponiendo que estás ejecutando la base de datos Sakila según las instrucciones, necesitas definir el controlador JDBC de MySQL, especificar la URL JDBC para localhost en el puerto 3306 y proporcionar el nombre de usuario ‘root’ y la contraseña ‘sakila’.
quarkus.datasource.jdbc.driver=com.mysql.cj.jdbc.Driverquarkus.datasource.jdbc.url=jdbc:mysql://localhost:3306/sakilaquarkus.datasource.username=rootquarkus.datasource.password=sakilaAdemás, recomiendo configurar hibernate-orm.log.sql en true, ya que esto asegurará que todas las consultas de Hibernate se registren, simplificando la inspección de las consultas de JPAStreamer más tarde.
quarkus.hibernate-orm.log.sql=true
5.2 Creando el Metamodelo de JPA
Para manipular los datos, necesitarás un modelo JPA con una entidad que represente cada tabla. Como esta no es una guía detallada de Hibernate, te aconsejo que tomes un atajo y generes algo de esqueleto JPA que solo necesita pequeñas modificaciones para adaptarse a tus necesidades. Si estás utilizando IntelliJ, puedes seguir mis pasos, de lo contrario, tendrás que consultar la documentación de tu IDE.
Comienza conectándote a la base de datos en IntelliJ navegando a Archivo > Nuevo > Origen de datos y seleccionando una instancia de MySQL. Luego completa los campos del diálogo con la misma URL de conexión, nombre de usuario y contraseña que en la sección anterior “Configurando Hibernate”.
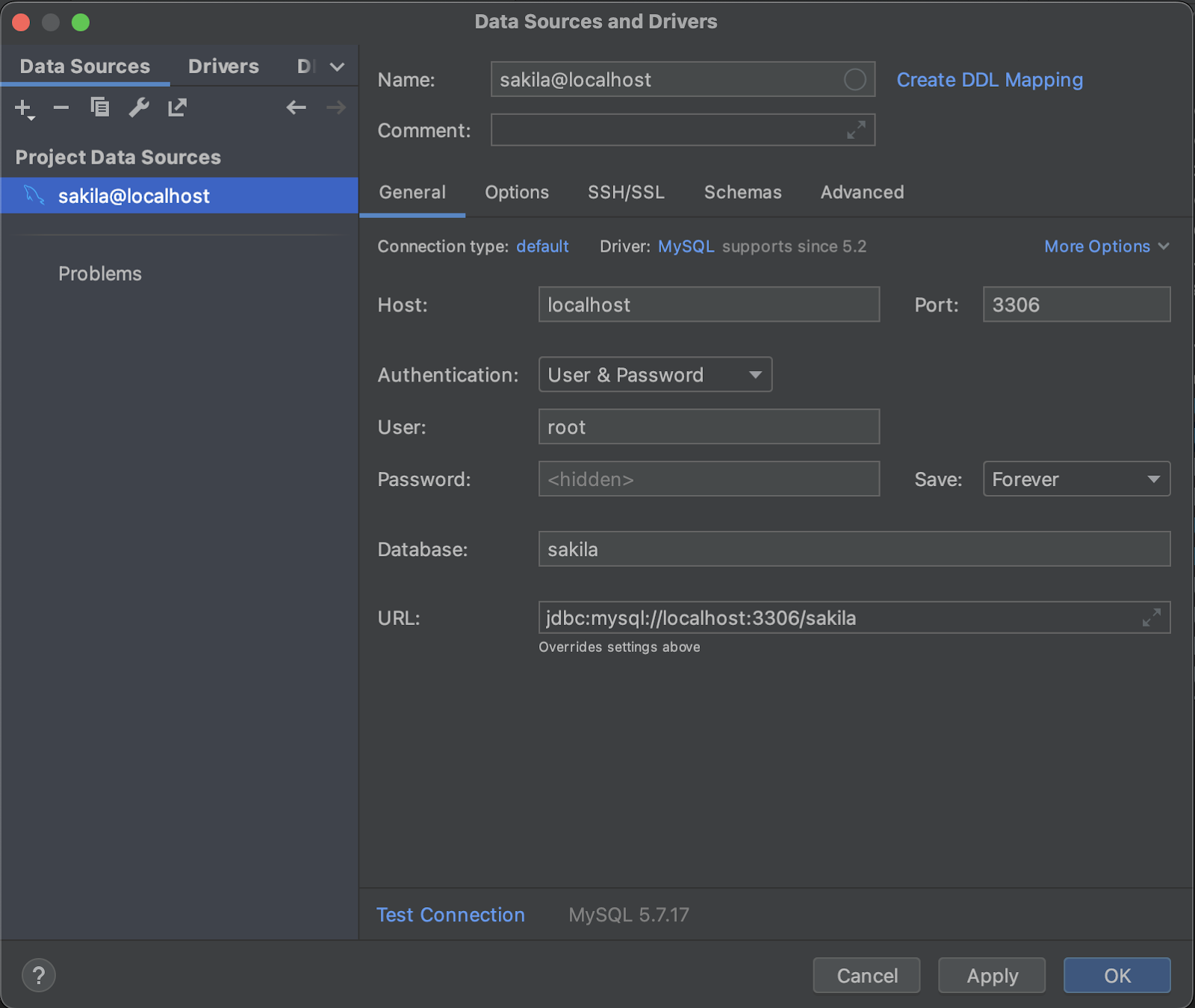
Después de presionar OK, deberías poder ver el contenido de la base de datos para confirmar que la conexión se estableció correctamente. Si la base de datos parece vacía a pesar de estar conectada, realiza una recarga de la base de datos para asegurarte de que los datos de la tabla se obtengan correctamente.
Ahora que nuestra base de datos está vinculada a IntelliJ, la generación de entidades es sencilla. Un simple clic derecho en la base de datos conectada te lleva a “Generar asignación de persistencia”. Selecciona dónde colocar tus entidades generadas (un paquete) y desmarca todas las tablas excepto Film y Actor, ya que son las únicas con las que trabajaremos. Haz clic en OK nuevamente y las entidades JPA para estas tablas se generan en un abrir y cerrar de ojos.
A continuación, necesitas realizar algunas modificaciones en las clases generadas. JPA ofrece una miríada de anotaciones para afinar estos mapeos, pero solo cubriré lo necesario para los fines de esta aplicación.
Comienza declarando a qué tabla y esquema se asignan las dos clases generadas de la siguiente manera:
@Table(name = "film", schema = "sakila")public class Film { … }@Table(name = "actor", schema = "sakila")public class Actor { … }Luego, elimina los campos de calificación (rating) y características especiales (special_features) de la clase Film.class, o mejora los mapeos para imponer algunas restricciones en los valores de la siguiente manera:
@Basic@Column(name = "rating", columnDefinition = "enum('G','PG','PG-13','R','NC-17')")private String rating;@Basic@Column(name = "special_features", columnDefinition = "set('Trailers', 'Commentaries', 'Deleted Scenes', 'Behind the Scenes')")private String specialFeatures;También debes definir manualmente la relación Many-to-Many entre las tablas Film y Actor. Esto requiere algunas actualizaciones en ambas clases.
Primero, la entidad Film requiere un campo llamado “actors” destinado a almacenar referencias a los actores que aparecen en una película específica. Esta conexión se establece a través del mapeo @ManyToMany y la anotación @JoinTable que describe la unión. Recuerda el nombre de la join_table y las claves foráneas del esquema en la introducción de la base de datos anteriormente.
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })@JoinTable( name = "film_actor", joinColumns = { @JoinColumn(name = "film_id") }, inverseJoinColumns = { @JoinColumn(name = "actor_id") })private List<Actor> actors = new ArrayList<>();De manera similar, la clase Actor necesita un campo “films” para almacenar el conjunto de películas en las que el actor ha protagonizado. Como ya has descrito la unión en la clase Actor, este campo solo necesita una referencia al mapeo anterior de la siguiente manera:
@ManyToMany(mappedBy = "actors")private Set<Film> films = new HashSet<>();Como paso final, genera los getters y setters para todos los campos tanto en la clase Film como en la clase Actor. Puedes elegir si hacerlo manualmente o generarlos con IntelliJ.
6. Configuración de JPAStreamer
JPAStreamer te permite crear consultas complejas de flujo de Java. Para convertir estas secuencias en consultas SQL durante la ejecución, JPAStreamer utiliza su metamodelo dedicado para crear predicados comprensibles. Aunque un lambda estándar podría servir para filtrar, le faltan los detalles requeridos para que JPAStreamer convierta el flujo de secuencias en una consulta.
En el ejemplo anterior, notarás el uso de una entidad llamada Film$. Esta entidad pertenece al metamodelo de JPAStreamer y te permite articular estos predicados sencillos que JPAStreamer comprende.
List<Film> films = jpaStreamer.stream(Film.class) .filter(Film$.title.startsWith("A") .and(Film$.length.greaterThan(60)) .limit(10) .collect(Collectors.toList());Afortunadamente, el metamodelo de JPAStreamer se crea automáticamente una vez que tienes un metamodelo de JPA en su lugar. Por lo tanto, simplemente continúa y reconstruye tu aplicación.
El metamodelo se encuentra en el directorio “target”, lo que significa que no se detectará como código fuente de forma predeterminada. Para solucionar esto, debes designar la carpeta “generated-sources” como una “Generated Sources Root” haciendo clic derecho sobre ella. Si todo va bien, tu carpeta “generated-sources” debería contener un Film$.class y un Actor$.class.
Ten en cuenta que si modificas tu modelo de JPA en algún momento, deberás reconstruir el proyecto para sincronizar los cambios con el metamodelo de JPAStreamer. También vale la pena mencionar que el nombre y la ubicación del metamodelo generado se pueden personalizar utilizando propiedades de variables de entorno. Puedes ver cómo se hace esto en la documentación de JPAStreamer.
7. Arquitectura de la Aplicación
Ahora es el momento de analizar la arquitectura de la aplicación. El objetivo es establecer puntos finales que sirvan información relacionada con las películas a los clientes. Con el fin de tener claridad y separación de responsabilidades, he elegido adoptar un Patrón de Repositorio sencillo.
A continuación, se muestra una instantánea de cómo encajarán las piezas arquitectónicas una vez que hayas terminado. La clase Resources asume la responsabilidad de entregar contenido derivado de la base de datos a los clientes. Sin embargo, esta clase se abstiene de realizar las interacciones reales con la base de datos; en su lugar, esta tarea se confía al Repositorio. Este enfoque arquitectónico separa de manera limpia la capa de datos de las demás facetas de nuestra aplicación.
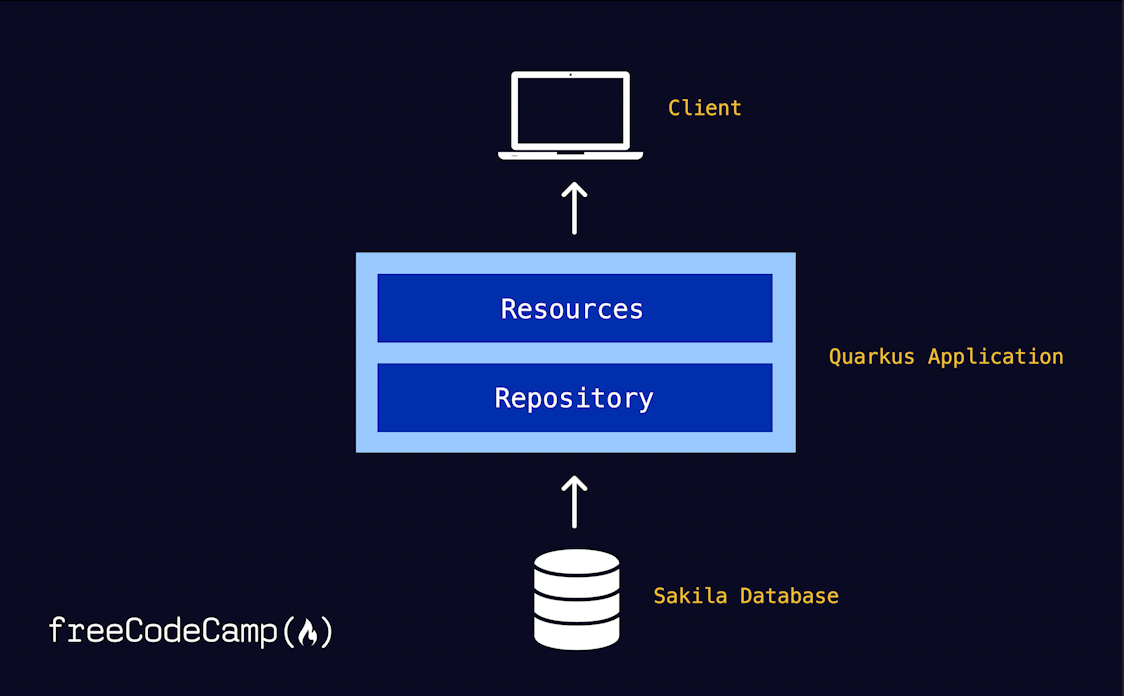
Esto se traduce en la siguiente jerarquía de archivos en la carpeta de tu proyecto una vez que hayas terminado:
quarkus-tutorial |- src | |- main | | |- java | | | |- com.freecodecamp.app | | | | |- FilmResource.java | | | | |- model | | | | |- Film.java | | | | |- Actor.java | | | | |- repository | | | | |- FilmRepository.java | | |- resources | | | | |- application.properties|- src7.¡Hola Mundo!
Para entender el ritmo de desarrollo con Quarkus, comencemos con la creación de un punto final clásico de “Hola Mundo”.
Empieza estableciendo la clase FilmResource, ubicada un nivel por encima de tu paquete de modelos de datos:
@Path("/")public class FilmResource { @GET @Path("/hello") @Produces(MediaType.TEXT_PLAIN) public String helloWorld() { return "¡Hola mundo!"; }}La anotación @Path asegura que tu servlet Resteasy se inicie junto con la aplicación y abre el punto final /hello para las solicitudes.
8. Ejecución en el modo de desarrollo de Quarkus
Con un punto final simple en su lugar, te sugiero iniciar la aplicación para validar la funcionalidad y disfrutar de la experiencia del modo de desarrollo de Quarkus. Usa el siguiente comando para iniciar la aplicación en tu terminal:
quarkus dev
Cuando tu aplicación se inicie, deberías recibir la bienvenida del terminal de Quarkus, lo que indica que tu aplicación se está ejecutando en el puerto predeterminado 8080 y que el código en vivo ha sido activado.
Listening for transport dt_socket at address: 5005__ ____ __ _____ ___ __ ____ ______ --/ __ \/ / / / _ | / _ \/ //_/ / / / __/ -/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \--\___\_\____/_/ |_/_/|_/_/|_|\____/___/2023-08-14 14:14:01,731 INFO [io.quarkus] (Quarkus Main Thread) quarkus-tutorial 1.0.0-SNAPSHOT en JVM (powered by Quarkus 3.1.3.Final) se inició en 2.210s. Escuchando en: http://localhost:80802023-08-14 14:14:01,733 INFO [io.quarkus] (Quarkus Main Thread) Perfil dev activado. Código en vivo activado.Ahora puedes visitar http://localhost:8080/hello para confirmar que recibes la respuesta esperada “¡Hola mundo!”.
Si esta es la primera vez que usas el modo de desarrollo de Quarkus, aprovecha la oportunidad y crea una copia de tu primer punto final. Un pequeño cambio, incluso algo tan pequeño como un solo carácter, será suficiente para diferenciarlo del original. A continuación, presiona la tecla [s] en tu terminal para reiniciar rápidamente la aplicación. El reinicio ocurre en un abrir y cerrar de ojos, dándote acceso a tu nuevo punto final momentos después en el navegador.
Este enfoque dinámico evita el temido escenario de acumular cambios solo para darse cuenta de que la aplicación no funciona después de compilar. Además, ya no necesitas soportar largos tiempos de compilación al hacer pequeños ajustes en algoritmos o fragmentos de código. Es un método realmente rápido y ágil para el desarrollo interactivo.
Antes de continuar, aquí tienes algunos comandos básicos que es bueno conocer:
[s] - Forzar reinicio[h] - Mostrar ayuda[q] - Salir9. Obtener Películas con Java Streams y JPAStreamer
Hasta ahora, nuestra aplicación no ha interactuado con la base de datos, pero eso es lo siguiente. Comenzaremos de forma simple y gradualmente construiremos consultas de Stream más poderosas.
Inicia este proceso estableciendo un paquete de repositorios dedicado junto al paquete de modelos existente. Dentro de esta sección de repositorios, crea una clase llamada FilmRepository. Como su nombre lo indica, esta clase servirá como el centro de nuestras consultas a la base de datos. Esta clase debe ser anotada con @ApplicationScoped para que pueda ser inyectada en tu FilmResource más adelante.
Luego, para comenzar a utilizar JPAStreamer, intégralo al repositorio inyectando una instancia de JPAStreamer. Esta instancia será tu punto de acceso a la API de consultas de Stream. Así es cómo debería verse tu clase en este punto:
@ApplicationScopedFilmRepository() { @Inject JPAStreamer jpaStreamer; ... }9.1 Obtener una entidad por su ID
El primer punto final buscará el título de una película dado un ID. Esta será tu primera oportunidad de aprovechar JPAStreamer para realizar consultas. Puedes pensar en una consulta de flujo como una tubería virtual que es recorrida por todas las películas en la base de datos. Las operaciones agregadas a la tubería determinarán qué entidades se permiten y en qué forma. Por ejemplo, una operación de filtro es equivalente a una cláusula WHERE, ya que impone una restricción lógica en las entidades resultantes.
Para iniciar una consulta de flujo, simplemente llama al método JPAStreamer.stream() y proporciona una fuente de tu elección. En este caso, nuestra fuente es la tabla Film, representada por la entidad Film.class. El valor de retorno de esta operación es un Stream<Film> estándar. Esto significa que, en la práctica, puedes aplicar cualquier operación de flujo disponible en la API de flujo para manipular las entidades de película.
Pero espera un momento, ¡tu elección de operaciones de flujo influye significativamente en el rendimiento, especialmente con conjuntos de datos grandes! Si estás familiarizado con la API de flujo, es probable que hayas encontrado numerosos ejemplos basados en lambdas para predicados y mapeos como este:
.filter(f -> f.getFilmId().equals(filmId))
Sin embargo, este predicado no puede ser optimizado por JPAStreamer, ya que la lambda anónima contiene pocos metadatos para realizar una traducción SQL correcta. Por lo tanto, conviértelo en un hábito expresar predicados utilizando el metamodelo de JPAStreamer. Guiado por IntelliSense en tu IDE, esto es simple:
.filter(Film$.id.equal(filmId))
Al ejecutar esta operación, se traducirá a una operación SQL WHERE para asegurarse de que el filtro se realice en la base de datos, no en la JVM, para mayor eficiencia.
Con este conocimiento, puedes seguir adelante y crear un método que obtenga películas basadas en su ID de la siguiente manera:
public Optional<Film> film(int filmId) { return jpaStreamer.stream(Film.class) .filter(Film$.filmId.equal(filmId)) .findFirst(); }Como antes, usa la tecla [s] para recargar tu aplicación en la terminal y navega a:
Si todo va bien, se te mostrará el título de la película:
ANACONDA CONFESSIONS
Una rápida mirada en el registro de la aplicación revela la consulta de Hibernate que fue emitida por JPAStreamer, confirmando la presencia de una operación WHERE.
Hibernate: select f1_0.film_id, f1_0.description, f1_0.language_id, f1_0.last_update, f1_0.length, f1_0.original_language_id, f1_0.rating, f1_0.rental_duration, f1_0.rental_rate, f1_0.replacement_cost, f1_0.special_features, f1_0.title from film f1_0 where f1_0.film_id=? limit ?9.2 Consultas paginadas
Cuando tienes un conjunto de datos considerable, enviar a los usuarios todos los resultados puede resultar poco práctico o incluso imposible. Ahí es donde entra en juego la paginación, limitando el conjunto de resultados. Con el uso de consultas de flujo en Java, la paginación se convierte en un esfuerzo sencillo. Puedes navegar entre páginas saltando datos anteriores con el operador skip() y limitar los resultados a un tamaño de página predefinido con limit().
Suponiendo un tamaño de página de 20, puedes facilitar el acceso del cliente a las películas que coinciden o superan una longitud especificada, manteniendo una secuencia ordenada basada en la longitud. Así es cómo:
private static final int PAGE_SIZE = 20; ...public Stream<Film> paged(long page, int minLength) { return jpaStreamer.stream(Film.class) .filter(Film$.length.greaterThan(minLength)) .sorted(Film$.length) .skip(page * PAGE_SIZE) .limit(PAGE_SIZE); }Para acomodar este contenido paginado, tu clase FilmResource necesita un nuevo punto final:
@GET@Path("/paged/{page}/{minLength}") @Produces(MediaType.TEXT_PLAIN) public String paged(long page, int minLength) { return filmRepository.paged(page, minLength) .map(f -> String.format("%s (%d min)", f.getTitle(), f.getLength())) .collect(Collectors.joining("\n")); }Una simple llamada a http://localhost:8080/paged/3/120 obtiene las películas en la tercera página, cada una con una duración mínima de 2 horas, produciendo una respuesta anticipada:
AMERICAN CIRCUS (129 min)UNFORGIVEN ZOOLANDER (129 min)...CHOCOLATE DUCK (132 min)STREAK RIDGEMONT (132 min)Un vistazo rápido en la terminal de desarrollo de Quarkus revela que todos los operadores de Stream se incorporaron en la consulta como operadores WHERE-, ORDER BY- y LIMIT con un valor inferior y superior:
Hibernate: select f1_0.film_id, f1_0.description, f1_0.language_id, f1_0.last_update, f1_0.length, f1_0.original_language_id, f1_0.rating, f1_0.rental_duration, f1_0.rental_rate, f1_0.replacement_cost, f1_0.special_features, f1_0.title from film f1_0 where f1_0.length>? order by f1_0.length limit ?, ?9.3 Proyecciones
Probablemente hayas notado que estás recuperando todo el array de columnas de la tabla Film, aunque solo incluyes el título y la duración en tu respuesta. Puedes ahorrar recursos de la aplicación utilizando una proyección como fuente de Stream en lugar de la tabla completa. El filmId es necesario ya que es la clave primaria.
public Stream<Film> paged(long page, int minLength) { return jpaStreamer.stream(Projection.select(Film$.filmId, Film$.title, Film$.length)) .filter(Film$.length.greaterThan(minLength)) .sorted(Film$.length) .skip(page * PAGE_SIZE) .limit(PAGE_SIZE);}Este cambio también requiere que mejores la entidad Film con un constructor correspondiente.
public Film(short filmId, String title, int length) { this.filmId = filmId; this.title = title; this.length = length;}Ahora, haz una segunda solicitud al punto final paged y observa cómo la consulta se limita a tres columnas.
http://localhost:8080/paged/3/120
Hibernate: select f1_0.film_id, f1_0.title, f1_0.length from film f1_0 where f1_0.length>? order by 3 limit ?, ?9.3 Uniones
Ahora pasemos a algo un poco más interesante: realizar una unión de Stream. Una unión es una combinación de varias tablas, traducida a consultas de Stream, lo que significa que debes actualizar la fuente de Stream para incluir entidades de una tabla adicional.
En la sección 5.2, definiste un mapeo entre la tabla Film y Actor a través del campo List<Actor> actors. Con JPAStreamer, puedes lograr una unión entre la tabla Film y Actor creando una StreamConfiguration<Film> que haga referencia a este campo de la siguiente manera:
StreamConfiguration<Film> sc = StreamConfiguration.of(Film.class).joining(Film$.actors);
La configuración del stream reemplaza ahora Film.class como fuente de stream. Aprovechando esto, también podemos agregar otro filtro y cambiar el orden de clasificación. Observa cómo se pueden combinar varios predicados con los operadores and/or.
public Stream<Film> actors(String startsWith, int minLength) { final StreamConfiguration<Film> sc = StreamConfiguration .of(Film.class).joining(Film$.actors); return jpaStreamer.stream(sc) .filter(Film$.title.startsWith(startsWith) .and(Film$.length.greaterThan(minLength))) .sorted(Film$.length.reversed());}Como respuesta a los clientes, parece apropiado presentar el título de las películas, la duración de las películas (para confirmar que el orden de clasificación es correcto) y una lista de los actores principales:
@GET@Path("/actors/{startsWith}/{minLength}")@Produces(MediaType.TEXT_PLAIN)public String actors(String startsWith, short minLength) { return filmRepository.actors(startsWith, minLength) .map(f -> String.format("%s (%d min): %s", f.getTitle(), f.getLength(), f.getActors().stream() .map(a -> String.format("%s %s", a.getFirstName(), a.getLastName())) .collect(Collectors.joining(", ")))) .collect(Collectors.joining("\n"));}Ahora prueba llamar al nuevo punto final con un carácter inicial A y una duración mínima de 2 horas: http://localhost:8080/actors/A/120. Debes esperar los siguientes resultados:
ANALIZAR HOOSIERS (181 min): TOM MCKELLEN, TOM MIRANDA, JESSICA BAILEY, GRETA MALDEN, ED GUINESSALLEY EVOLUTION (180 min): KARL BERRY, JUDE CRUISE, ALBERT JOHANSSON, GREGORY GOODING, JOHN SUVARI...ALAMO VIDEOTAPE (126 min): JOHNNY CAGE, SCARLETT DAMON, SEAN GUINESS, MICHAEL BENINGARIZONA BANG (121 min): KARL BERRY, RAY JOHANSSON, RUSSELL BACALL, GRETA KEITELA continuación se muestra la consulta resultante, confirmando que se aplicó la unión.
Hibernate: select f1_0.film_id, a1_0.film_id, ... from film f1_0 left join (film_actor a1_0 join actor a1_1 on a1_1.actor_id=a1_0.actor_id) on f1_0.film_id=a1_0.film_id where f1_0.title like replace(?,'\\','\\\\') and f1_0.length>? order by f1_0.length desc9.4 Actualización de películas
Aunque la fortaleza de JPAStreamer radica en la lectura de datos, también puedes usarlo para actualizar tu base de datos. Digamos que la tienda de alquiler de videos imaginada tiene un modelo de precios basado en la duración de las películas. En ese caso, querrías poder ajustar la tarifa de alquiler según la duración. Esto se logra fácilmente filtrando las películas relevantes y aplicando el operador forEach() para establecer un nuevo precio. Al anotar el método con @Transactional, te aseguras de que Hibernate persista los cambios en tus entidades de Film.
@Transactionalpublic void updateRentalRate(int minLength, int maxLength, BigDecimal rentalRate) { jpaStreamer.stream(Film.class) .filter(Film$.length.between(minLength, maxLength)) .forEach(f -> { f.setRentalRate(rentalRate); });}Te dejo a ti crear un punto final que facilite a los clientes iniciar actualizaciones de tarifas de alquiler.
10. Pruebas Continuas
Puedes configurar Quarkus para que desencadene automáticamente la ejecución de tu suite de pruebas JUnit cada vez que ejecutes tu aplicación. O alternativamente, desencadena la ejecución manualmente presionando [r] en la terminal de desarrollo de Quarkus. Antes, entendía el valor del desarrollo impulsado por pruebas (TDD) pero siempre sentí que obstaculizaba el enfoque en la lógica empresarial, ya que solo las ejecutaba ocasionalmente. Esto no significa que Quarkus escriba las pruebas por ti, pero son fáciles de ejecutar y el modo de desarrollo te recuerda constantemente que están ahí.
Tanto pruebas de integración como pruebas unitarias.
Aunque inicialmente expuse los requisitos para este tutorial, hay algunos detalles importantes a tener en cuenta cuando se trata de pruebas continuas. Si utilizaste el configurador de proyectos Quarkus según lo descrito en este tutorial, es probable que ya estés configurado. De lo contrario, asegúrate de que:
- Dependes del módulo Quarkus JUnit 5
- Defines una versión del complemento Maven Surefire (por ejemplo, 3.0.0), ya que la versión predeterminada no tiene soporte para JUnit 5
- (Opcional) Rest-assured para pruebas simples de puntos finales REST
Para cumplir con los requisitos anteriores, verifica que tengas las siguientes dependencias y configuraciones de complementos en tu pom.xml:
<dependencies> <dependency> <groupId>io.quarkus</groupId> <artifactId>quarkus-junit5</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>io.rest-assured</groupId> <artifactId>rest-assured</artifactId> <scope>test</scope> </dependency>…</dependencies>…<build> <plugins> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0</version> <configuration> <systemPropertyVariables> <java.util.logging.manager> org.jboss.logmanager.LogManager </java.util.logging.manager> <maven.home>${maven.home}</maven.home> </systemPropertyVariables> </configuration> </plugin> …. </plugins></build>Las pruebas de Quarkus se colocan como sus pruebas JUnit regulares en la carpeta de pruebas estándar, es decir, /src/test/java si está utilizando Maven como herramienta de construcción. La única diferencia real es que necesita anotar sus clases de prueba con @QuarkusTest para que Quarkus reconozca las pruebas. Las siguientes secciones contienen ejemplos de cómo crear pruebas unitarias e de integración.
10.1 Pruebas Unitarias
No hay nada especial en la creación de pruebas unitarias con Quarkus aparte del hecho de que pueden ejecutarse rápidamente en el modo de desarrollo. Para probar el FilmRepository, simplemente puedes inyectarlo en tu clase de prueba como lo hiciste en FilmResource y llamar a los métodos CRUD.
Aquí tienes un ejemplo de una prueba que asegura que tu método getFilm() recupere una película con el título “AFRICAN EGG”.
@QuarkusTestpublic class FilmRepositoryTest {
@Inject
FilmRepository filmRepository;
@Test
public void test() {
final Optional<Film> film = filmRepository.getFilm(5);
assertTrue(film.isPresent());
assertEquals("AFRICAN EGG", film.get().getTitle());
}
}10.2 Pruebas de Integración REST
Quarkus también facilita las pruebas de integración sin esfuerzo de tus puntos finales REST. Al aprovechar la biblioteca rest-assured, de la que se habló en la sección anterior, tienes acceso a una API rica diseñada para las pruebas de REST.
El siguiente ejemplo recuerda a la prueba unitaria anterior, pero en forma de prueba de integración. Al ejecutarse, Quarkus emitirá automáticamente una solicitud GET a tu punto final de películas, apuntando a una película con ID 5. La prueba espera una respuesta exitosa (código de estado HTTP 200) y verifica que el cuerpo de la respuesta contenga el título de la película, “AFRICAN EGG”.
@QuarkusTestpublic class FilmResourceTest {
@Test
public void test() {
given()
.when().get("/film/5")
.then()
.statusCode(200)
.body(containsString("AFRICAN EGG"));
}
}10.3 Ejecución de las Pruebas
Suponiendo que todavía estás ejecutando en el modo de desarrollo de Quarkus, puedes usar uno de estos comandos para controlar la fase de prueba:
[r] - Volver a ejecutar todas las pruebas[f] - Volver a ejecutar las pruebas que fallaron[v] - Mostrar fallos de la última ejecución de pruebasLos resultados de las pruebas se registrarán en los registros de Quarkus:
Todas las pruebas son exitosas (0 omitidas), se ejecutaron 1 pruebas en 336 ms. Pruebas completadas a las 17:34:25 debido a cambios en FilmRepository.class.
Si deseas que las pruebas se ejecuten cada vez que se detecte un cambio en la aplicación, puedes configurar quarkus.test.continuous-testing=enabled en application.properties.
También tienes la opción de ejecutar tus pruebas cuando no estés en ejecución en modo de desarrollo utilizando el comando:
mvn quarkus:test
11. Ejecución del Depurador con el Modo de Desarrollo Quarkus
Frecuentemente, una prueba puede fallar sin una causa aparente, dejándonos perplejos (o quizás no tanto). Irónicamente, a veces me encuentro atribuyendo mis propios errores simples a errores de bibliotecas externas. Afortunadamente, el depurador viene al rescate, arrojando luz sobre dónde las cosas se torcieron y a menudo humillándome al revelar mis propios errores.
Si deseas utilizar el depurador de IntelliJ en conjunto con el modo de desarrollo de Quarkus, debes adjuntar el depurador manualmente. Este proceso es sencillo pero implica crear una configuración de ejecución personalizada. Ve a Ejecutar > Editar Configuraciones y genera una nueva configuración de Depuración Remota de JVM. Elige una etiqueta clara como “Depurar Quarkus” para distinguirla fácilmente de otras configuraciones. Como Quarkus designa el puerto 5005 para las sesiones de depuración, simplemente debes especificar que deseas vincularte a un JVM remoto en localhost:5005, como se muestra en la imagen siguiente.
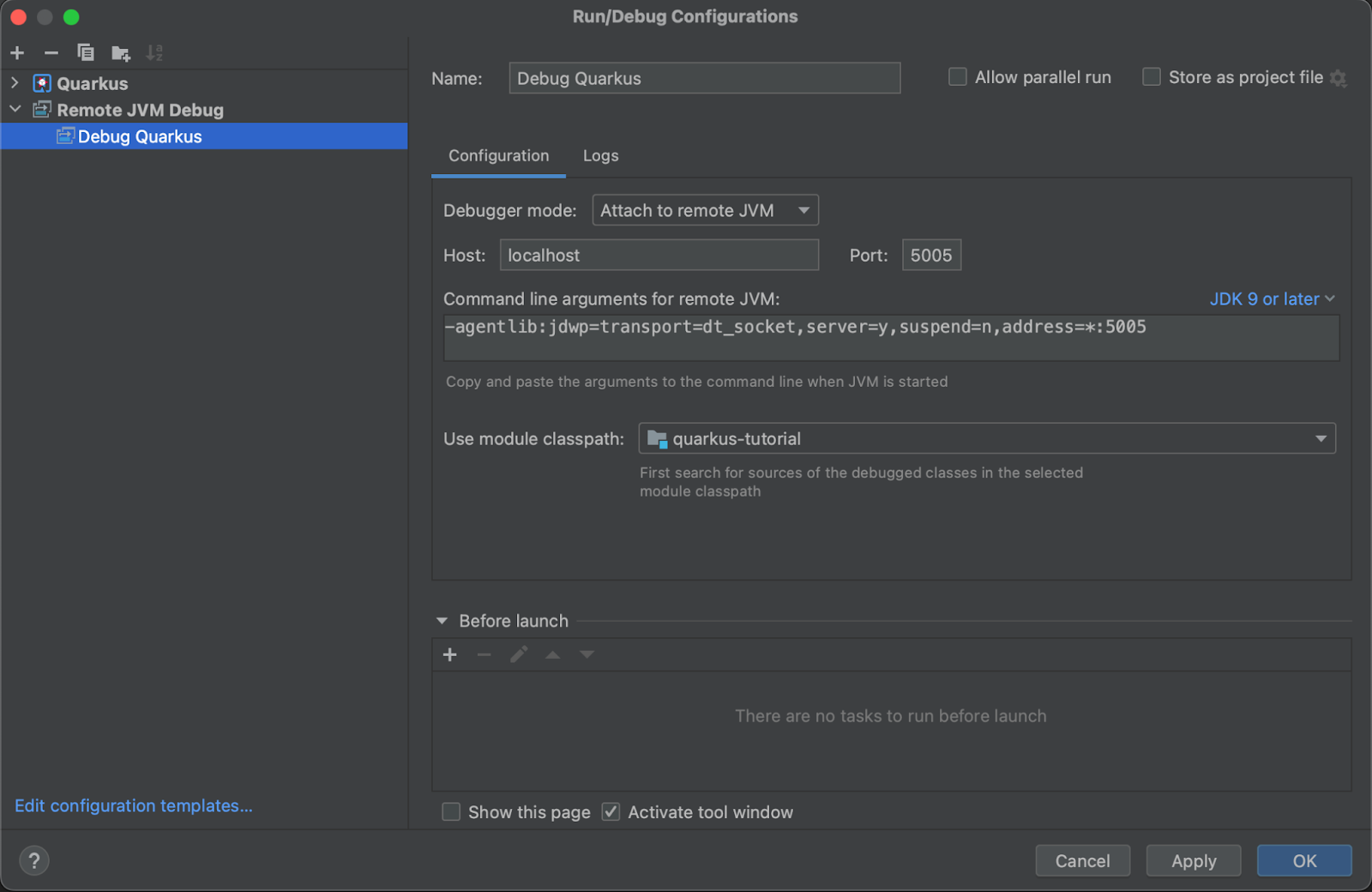
Una vez que esta configuración esté lista, reinicie Quarkus en el modo de desarrollo de depuración de la siguiente manera:
./mvnw compile quarkus:dev -Ddebug
Luego, ejecute su nueva configuración de depuración de Quarkus en IntelliJ para conectarse al proceso de Quarkus y proceder a usar el depurador como de costumbre.
12. Construyendo tu aplicación
Aunque el conjunto de funciones de nuestra aplicación podría ser modesto en esta etapa, es completamente funcional y está listo para potencialmente ofrecer a los usuarios acceso a información relacionada con películas. Con esto en mente, es un momento adecuado para prepararse para la implementación.
Quarkus ofrece dos opciones de construcción distintas: el compilador Quarkus JIT HotSpot y la construcción nativa de Quarkus impulsada por Graal VM. El primero mejora el compilador JIT de Java estándar para un rendimiento óptimo, mientras que el último aprovecha la compilación anticipada (AOT), maximizando la eficiencia de compilación sobre la ejecución en tiempo de ejecución. Si bien la imagen a continuación es un activo de marketing proporcionado por Quarkus, mis propios experimentos confirman las ganancias de rendimiento tangibles que muestra.
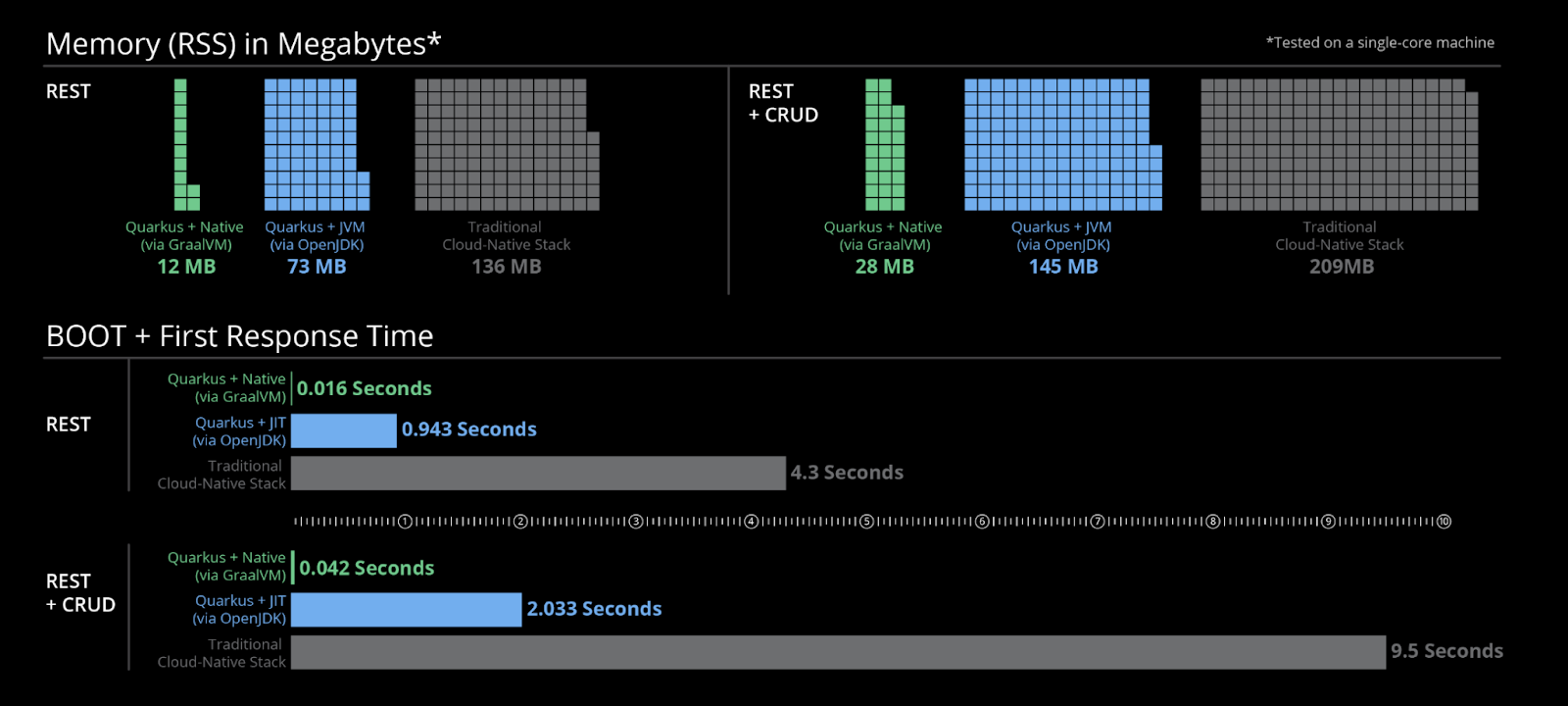
12.1 Construcción JIT de Quarkus mediante OpenJDK
Dado que ya ha desarrollado su proyecto utilizando la plataforma Quarkus, tiene acceso inmediato al compilador JIT sin necesidad de ningún paso adicional. La ilustración anterior brinda una idea de las mejoras significativas que Quarkus ha realizado en el compilador estándar, potencialmente cumpliendo con sus requisitos de optimización.
Para iniciar el proceso de construcción estándar de Quarkus, simplemente ejecute el siguiente comando:
`quarkus build`
La construcción resultante se almacena en /target/quarkus-app. Sin embargo, es importante tener en cuenta que el JAR generado no es un “über-jar” y, por lo tanto, carece de funcionalidad independiente. Para una implementación exitosa, asegúrese de incluir toda la carpeta quarkus-app para garantizar la disponibilidad de todos los recursos necesarios.
Cuando esté listo para ejecutar su aplicación, emplee el siguiente comando:
java -jar /target/quarkus-run.jar
Preste atención al indicador de Quarkus que muestra el tiempo que tardó en iniciar su aplicación. Como referencia, me llevó alrededor de 1.7 segundos iniciar la versión compilada JIT de esta aplicación.
12.2 Construcción nativa de Quarkus mediante GraalVM
Ahora, adentrémonos en el aspecto más interesante de Quarkus: el proceso de construcción nativa. Aunque compilar en modo nativo no requiere esfuerzo adicional por parte suya como desarrollador, sí requiere un poco de paciencia. La compilación anticipada (AOT) lleva considerablemente más tiempo que la construcción estándar de HotSpot del JVM. La compilación nativa actúa como un compresor potente, mejor reservado para cuando esté preparándose para implementar una nueva iteración de su software.
Dado que Quarkus ha introducido la opción de construir de forma nativa utilizando una variante contenerizada de GraalVM, no profundizaré en las instrucciones de instalación de GraalVM. Para ejecutar una construcción nativa utilizando el contenedor Docker de GraalVM, emita el siguiente comando:
./mvnw package -Pnative -Dquarkus.native.container-build=true
Alternativamente, si tiene GraalVM localmente, puede continuar con la versión local:
./mvnw package -Pnative
El archivo ejecutable creado por la construcción nativa funciona no como una aplicación basada en JVM, sino como una aplicación nativa específica de la plataforma. Para ejecutarlo, simplemente ejecute el script de ejecución ubicado en la raíz de la carpeta target (El nombre de archivo corresponde al nombre de su aplicación):
./target/quarkus-tutorial-1.0.0-SNAPSHOT-runner
Nuevamente, observe el indicador de Quarkus para ver cuánto tiempo tardó en iniciar la versión nativa. ¡En mi caso, se redujo a aproximadamente una décima parte de un segundo!
13. Recursos
- Configurador de proyecto Quarkus
- Documentación de Quarkus
- Documentación de JPAStreamer
- Código fuente completo del proyecto










Leave a Reply