Como Manejar el Procesamiento de Nombres Multilingües en tus Aplicaciones
A principios de este año, mi equipo de trabajo y yo estábamos revisando los errores que ocurrían en uno de nuestros APIs de registro. Vimos que casi el 5% de nuestras solicitudes fallaban, todas debido a errores de BAD REQUEST [https//developer.mozilla.org/en-US/docs/Web/HTTP/Status/400]. Y la causa raíz fue rastreada hasta una expresión regular.
Earlier this year, mi equipo de trabajo y yo estábamos revisando los errores que ocurrían en una de nuestras API de registro. Vimos que casi el 5% de nuestras solicitudes fallaban, todas debido a errores de 400 BAD REQUEST. Y la causa principal se remontaba a una verificación de regex.
Este regex era una restricción, donde nuestro sistema solo permite que las personas utilicen caracteres en inglés para ingresar sus nombres y apellidos. El problema era que muchas personas optaban por ingresar sus nombres en sus idiomas nativos.
Estos clientes eran personas interesadas en comprar pólizas de salud en nuestra plataforma, lo que los convertía en un segmento crucial de nuestra base de usuarios.
En respuesta a esto, decidimos abordar estos usuarios y permitirles ingresar sus nombres en cualquier idioma que prefirieran. Pero esto planteó muchos desafíos que necesitábamos resolver, y aquí voy a explicar cómo lo hicimos.
Desafíos con el procesamiento de nombres multilingües
1. Estrategia de almacenamiento de datos
Dependemos de MongoDB para almacenar y recuperar nombres de usuarios. Si bien MongoDB permite el almacenamiento de todos los caracteres compatibles con UTF-8, el problema surge al tratar con la búsqueda.
Para nombres en inglés, nuestras operaciones de búsqueda utilizan el método de colación simple. Los campos correspondientes están indexados de manera adecuada para optimizar el rendimiento de las consultas.
Aunque también existe la opción de implementar un índice de colación para otros idiomas en MongoDB, este enfoque requiere informar a la base de datos sobre el idioma específico para el que se pretende buscar. El desafío aquí es que nuestra base de usuarios abarca muchos idiomas, siendo India solo uno de ellos con más de 20 idiomas diversos.
Nuestro objetivo era brindar soporte al menos para todos los idiomas de India. Pero esto significaba que implementar índices de colación para cada idioma compatible aumentaría el número de índices, y también el tamaño del índice con el tiempo.
Este enfoque también requeriría que los desarrolladores recuerden agregar un índice para cada nuevo idioma a medida que nuestro soporte de idiomas se expande, lo cual está muy lejos de ser una solución eficiente.
2. Restricción de API Gateway
Todas nuestras API están expuestas detrás de un API gateway. Justo antes de que el gateway envíe una solicitud al servicio de API respectivo, una política de entrada verifica el estado de autenticación del usuario. Una vez que el usuario está autenticado, se recuperan los detalles básicos del usuario, como el nombre, el número de teléfono móvil y otros metadatos, y se agregan al encabezado de esa solicitud de API.
Muchas API dependen de estos datos específicos del usuario en los encabezados para su procesamiento posterior.
Pero hay una restricción impuesta por el gateway: solo permite caracteres ASCII para su procesamiento e inclusión en los encabezados. Por lo tanto, tuvimos que asegurarnos de que, aunque el nombre pudiera estar en cualquier otro idioma, la respuesta que compartíamos tuviera que ser exclusivamente en inglés.
Además, este proceso debía ser rápido, ya que cualquier retraso en la autenticación podría afectar el rendimiento lento de la API.
3. Desafío de los socios externos con nombres vernáculos
Incluso si comenzábamos a aceptar nombres en varios idiomas, había socios nuestros que tenían que aceptar esos nombres de nuestra parte. Si no admiten nombres multilingües, se interrumpiría el recorrido del usuario.
Un ejemplo de ello fue nuestro socio de pagos. Tuvimos que asegurarnos de que nuestro equipo de pagos siempre recibiera el nombre en inglés, incluso cuando los usuarios proporcionaran nombres en otros idiomas.
También queríamos evitar esas molestas ventanas emergentes que pedían a los usuarios que ingresaran sus nombres en inglés siempre que fuera posible. Por lo tanto, teniendo en cuenta estos problemas, tuvimos que construir una solución viable.
Cómo resolvimos estos desafíos
Si bien utilizar un servicio de transliteración de terceros podría haber sido la ruta más fácil, optamos por desarrollar una solución interna para controlar los costos y mantener un control total.
Teniendo en cuenta el API gateway y los requisitos de los socios de pagos, quedó claro que necesitábamos transformar los nombres no ingleses en equivalentes en inglés. Pero presentar este nombre en inglés al usuario era contradictorio: por ejemplo, ingresar un nombre en hindi y verlo transformado en inglés al iniciar sesión no tenía sentido.
Para manejar esto, desarrollamos una estrategia de doble nombre. Los campos originales, "firstName" y "lastName", conservarían los nombres ingresados por el usuario en el idioma ingresado. Luego, introdujimos dos campos adicionales, "englishFirstName" y "englishLastName", dedicados a almacenar los equivalentes en inglés de estos nombres. Estos nombres en inglés podrían compartirse con el API gateway y nuestros socios de pagos.
Volviendo al desafío de almacenar estos nombres de manera eficiente, anticipamos que la administración de índices de colación a medida que aumentaba el número de idiomas compatibles se volvería inmanejable. La búsqueda también requeriría especificar la colación para cada consulta, creando una capa adicional de complejidad. Por lo tanto, decidimos alejarnos de este enfoque.
Nuestro segundo enfoque involucró el uso de Unicode. Como nuestro objetivo era soportar varios idiomas sin restricciones, reconocimos que Unicode podía representar eficazmente caracteres en casi todos los idiomas. Por esta razón, decidimos almacenar representaciones Unicode para nombres y apellidos en sus respectivos campos de MongoDB.
Agregamos simplemente otra capa entre nuestra base de datos y la aplicación. Convierte estas cadenas Unicode a los valores originales en el idioma local al recuperar los nombres de la base de datos y convierte los nombres locales a sus respectivos nombres en inglés. Luego los almacena en englishFirstName y englishLastName al momento de cualquier inserción o actualización.
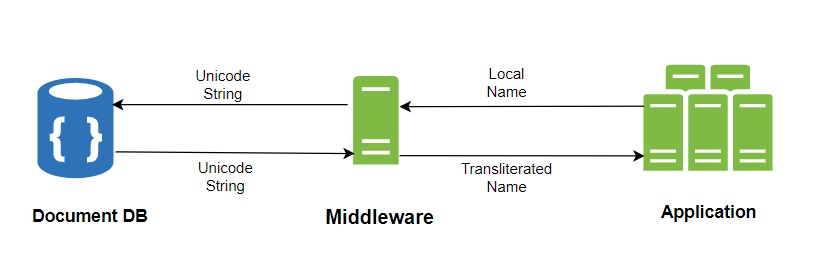
Esta estrategia nos brindó la flexibilidad que necesitábamos para administrar nombres multilingües de manera fluida.
Consideraciones clave de diseño
1. Optimización Unicode
Típicamente, la representación Unicode consta de una cadena de 6 caracteres, donde ‘a’ se representa como ‘U+0061’ y ‘P’ como ‘U+0050’, comúnmente comenzando con ‘U+00’. Para conservar espacio en el almacenamiento de nuestra base de datos, optamos por omitir el prefijo ‘U+’ y los ceros iniciales, optimizando nuestro almacenamiento de datos.
2. Transliteración vs. Traducción
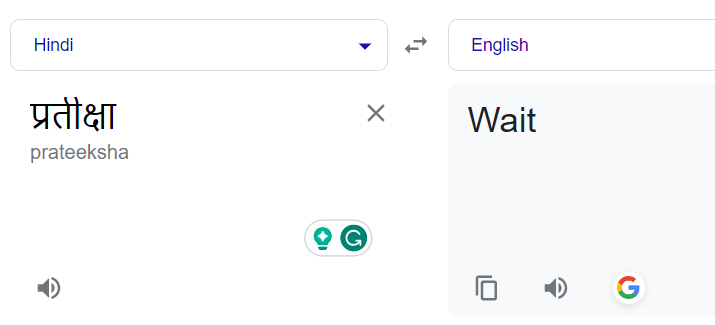
Inicialmente, nuestro objetivo era la transliteración, que requiere convertir nombres de un script a otro mientras se retiene su sonido fonético. Por ejemplo, la palabra en hindi "प्रतीक्षा" debería transformarse en "Partiksha" y no traducirse a su equivalente en inglés, "Wait".
Pero reconocimos que Google Translate se enfoca principalmente en la traducción, no en la transliteración. Nuevamente, no queríamos usar directamente el servicio de transliteración pago de Google en nuestra primera iteración, así que desarrollamos nuestro propio servicio de transliteración utilizando la versión gratuita de Google Translate.
3. Mejoras Contextuales
Otra observación crucial que tuvimos fue brindar contexto a la API de Google Translate, lo cual influyó en sus respuestas.
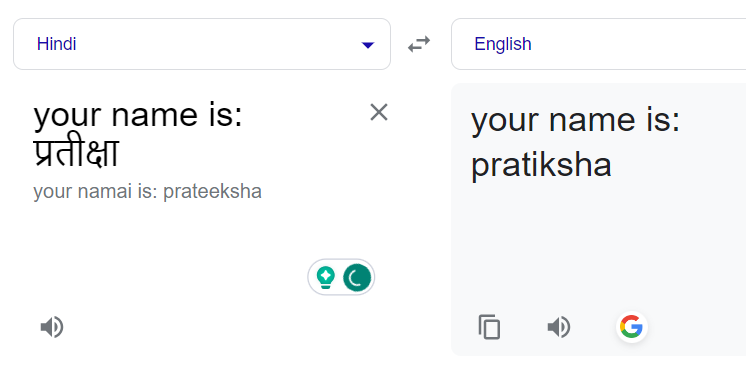
Para aprovechar esto, experimentamos agregando prefijos a los nombres que no eran en inglés para establecer contexto. Después de algunos intentos y errores, nos dimos cuenta de que para nombres más cortos (menos de 5 caracteres), un prefijo más extenso no daba resultados deseables y Google a menudo devolvía la misma palabra en hindi. Para nombres más largos, empleamos declaraciones más extensas, determinando el equilibrio óptimo a través de prueba y error.
La traducción normal de los nombres llevaba a su traducción literal. Por ejemplo, “प्रतीक्षा” a “Wait” en lugar de “Pratiksha”:
Agregar una declaración de prefijo lo corrigió:
De acuerdo, ahora veamos cómo implementamos todo esto en realidad.
Código inicial
Después de nuestra primera iteración, desarrollamos el siguiente código para la transliteración. Aquí estamos usando la biblioteca @iamtraction/google-translate que es una capa escrita sobre la API gratuita de Google Translate.
const translate = require('@iamtraction/google-translate');function getGoogleTranslateText(localName) { /* Agregando una oración en inglés antes del nombre para que no se traduzca a su significado literal. Por ejemplo, परीक्षा se convierte en Exam en lugar de Pariksha. */ if (localName.length <= 5) { return `nombre: ${localName}`; } return `tu nombre es: ${localName}`;}async function translateNameToEnglish(localName) { if (localName.match(/^[a-zA-Z ]+$/i)) { // Si el nombre ya está en inglés, simplemente devolverlo return localName; } try { const res = await translate(getGoogleTranslateText(localName), { to: 'en', }); const translatedName = res.text.split(':')[1].trim(); return translatedName; } catch (err) {} // En caso de error, devolver la cadena Unicode return localName;}Lanzamiento beta y desafíos de producción
Una vez que construimos esto, lanzamos la función en versión beta y aproximadamente 250 usuarios se registraron con nombres en otros idiomas en los primeros días.
Después de echar un vistazo rápido a algunos textos traducidos, descubrimos que el proceso de convertir el nombre de su idioma local a Unicode funcionaba perfectamente bien y los usuarios podían ver sus nombres correctamente en la aplicación en el idioma que preferían.
Sin embargo, identificamos dos problemas en cuanto al proceso de transliteración al inglés:
- Algunos nombres se transliteraban incorrectamente. Este problema se debía a nuestra dependencia de Google Translate, un servicio de traducción general, en lugar de un servicio de transliteración especializado.
- Algunos nombres permanecían sin cambios y no se transliteraban. Estos nombres se devolvían en el mismo idioma que el original. Esto significaba que agregar contexto con frases de prefijo antes de la traducción estaba causando problemas para nombres específicos.
Esto nos llevó a una investigación adicional que nos llevó a otro paquete de npm llamado “unidecode”, que convierte Unicode en la cadena original. Si bien las pruebas iniciales con unidecode mostraron precisión, también revelaron pequeñas discrepancias en la ortografía. En contraste, Google siempre entregaba traducciones con las ortografías correctas. Solo necesitábamos encontrar una manera de aprovechar lo mejor de ambos mundos.
Así que incorporamos unidecode en nuestro algoritmo como parte de nuestra solución.
Solución mejorada
Esto es lo que se nos ocurrió:
const translate = require('@iamtraction/google-translate');
const unidecode = require('unidecode');
const { isAlmostEqualStrings } = require('./levenshtein');
/**
* @param {String} localName
* @description Genera texto para Google (declaración de contexto más corta para nombres cortos) basado en la longitud de localName
* @returns {String} devuelve el texto a traducir
*/
function getGoogleTranslateText(localName) {
/*
Agregando una oración en inglés antes del nombre para que no se traduzca a su significado literal.
Por ejemplo, परीक्षा a Exam en lugar de Pariksha.
*/
if (localName.length <= 5) {
return `nombre: ${localName}`;
}
return `tu nombre es: ${localName}`;
}
/**
* @param {String} localName
* @description Devuelve un nombre transliterado CASI
* @returns {String} devuelve un nombre transliterado convertido del idioma local
*/
function transliterate(localName, googleTranslatedName) {
const decodedName = unidecode(localName);
if (
decodedName &&
Array.from(decodedName)[0]?.toLowerCase() !==
Array.from(googleTranslatedName)[0]?.toLowerCase() &&
!isAlmostEqualStrings(decodedName, googleTranslatedName)
) {
return decodedName;
}
return googleTranslatedName;
}
/**
* @param {String} Cadena no inglesa de entrada
* @description traduce una cadena no inglesa al inglés
* @returns {String} devuelve una cadena traducida
*/
async function translateNameToEnglish(localName) {
if (!localName || localName.match(/^[a-zA-Z ]+$/i)) {
// Si el nombre ya está en inglés, simplemente regresar
return localName;
}
try {
const res = await translate(getGoogleTranslateText(localName), {
to: 'en',
});
const translatedName = res.text.split(':')[1].trim();
return transliterate(localName, translatedName);
} catch (err) {}
// En caso de error, devuelve la cadena original
return localName;
}Después de obtener el nombre traducido, lo alimentamos a la función transliterate recientemente introducida. Dentro de esta función, nuestro primer paso consiste en extraer la cadena decodificada utilizando la biblioteca Unidecode. Pero entonces surge la cuestión principal: ¿cómo determinamos qué resultado priorizar, la cadena decodificada o la cadena traducida?
Para abordar esto, implementamos la Distancia de Levenshtein, un algoritmo que calcula la similitud entre dos cadenas.
Inicialmente, comprobamos si el primer carácter del nombre decodificado coincide con el primer carácter del nombre traducido. Si no coincide, entonces es seguro que el nombre traducido es incorrecto, por lo que devolvemos el nombre decodificado. Aunque puede contener pequeñas discrepancias ortográficas, es mejor usarlo que una traducción incorrecta.
Si coincide, luego utilizamos el algoritmo de Distancia de Levenshtein.
La distancia de Levenshtein es un número que indica qué tan similares son dos cadenas. Cuanto mayor sea el número, más diferentes son las dos cadenas.
En la implementación, tenemos una función isAlmostEqualStrings que genera un valor de 0 a 1 y devuelve verdadero si el valor está por encima de cierto umbral. En nuestro caso, establecemos el umbral en 0.8.
Si la distancia de Levenshtein indica una coincidencia superior al 80%, devolvemos el nombre traducido. De lo contrario, devolvemos el nombre decodificado. Este enfoque garantiza que prioricemos la precisión, ofreciendo un resultado confiable basado en el umbral de similitud establecido.
Este algoritmo actualizado redujo sustancialmente los problemas mencionados anteriormente. Aunque no es 100% preciso, resolvió muy bien nuestros casos del 5%.
Conclusión
El algoritmo que desarrollamos fue completamente interno y no incurrió en costos. Si bien invertir en una solución paga podría haber ofrecido potencialmente mejores resultados, decisiones de ingeniería sabias tomadas de manera iterativa y un puñado de trucos inteligentes desempeñaron un papel vital tanto en la reducción de costos como en la resolución eficiente del problema específico que teníamos.
El código completo de la implementación anterior junto con el algoritmo de Distancia de Levenshtein se puede encontrar en GitHub (se aceptan contribuciones/correcciones).
Con esto, llegamos al final del artículo. Mis mensajes directos siempre están abiertos si deseas discutir más sobre cualquier tema tecnológico o si tienes alguna pregunta, sugerencia o comentario en general:
¡Feliz aprendizaje!








Leave a Reply