Manual de Estructuras de Datos La Clave para un Software Escalable
Si te enfrentas regularmente a la complejidad de los datos modernos, no estás solo/a. En nuestro mundo centrado en los datos, entender las estructuras de datos no es una opción, es esencial. Ya seas un/una programador/a novato/a o un desarrollador/a experimentado/a, este manual es tu guía concisa para la habilidad crítica de la gestión de datos a través de las estructuras de datos. Datos
Si te enfrentas regularmente a la complejidad de los datos modernos, no estás solo. En nuestro mundo centrado en los datos, comprender las estructuras de datos no es opcional, es esencial.
Ya seas un programador novato o un desarrollador experimentado, este manual es tu guía concisa para la habilidad fundamental de la gestión de datos a través de estructuras de datos.
Hoy en día, los datos no solo son vastos, también son complejos. Organizar, recuperar y manipular eficientemente estos datos es clave. Aquí es donde entran las estructuras de datos, la columna vertebral de una gestión de datos efectiva.
Esta guía desmenuza la complejidad de los arrays, listas enlazadas, pilas, colas, árboles y grafos. Obtendrás información sobre las fortalezas, limitaciones y aplicaciones prácticas de cada tipo, respaldado por ejemplos del mundo real.
Incluso los grandes cerebros en lugares como el MIT y Stanford dicen que conocer tus estructuras de datos es superimportante para crear un buen software. Y aquí, compartiré casos de estudio de la vida real que te mostrarán cómo se utilizan estas estructuras de datos en situaciones cotidianas.
¿Listo para sumergirte? Vamos a explorar juntos el mundo de las estructuras de datos. Descubrirás cómo hacer que tus datos trabajen de manera más inteligente, no más duro, y te darás una ventaja en el mundo tecnológico.
A continuación, el increíble viaje en el que estás a punto de embarcarte:
Consigue el trabajo de tus sueños en tecnología: Imagina ingresar con confianza a grandes nombres como Google o Apple. Tus nuevas habilidades en estructuras de datos podrían ser tu boleto de oro para estos refugios tecnológicos, donde realmente importa saber de qué hablas.
Compra en línea fácilmente: ¿Alguna vez te has preguntado cómo Amazon hace que las compras sean tan sencillas? Con tus habilidades, podrías ser el mago detrás de experiencias de compras más rápidas e inteligentes.
Conviértete en un genio financiero: Los bancos y las compañías de finanzas adoran el manejo rápido y sin errores de los datos. Tu conocimiento podría convertirte en una estrella en lugares como Visa o PayPal, manteniendo el dinero en movimiento de manera rápida y segura.
Revoluciona la atención médica: En el mundo de la salud, como en Mayo Clinic o Pfizer, tu capacidad para gestionar datos podría acelerar las decisiones que salvan vidas. Podrías formar parte de un equipo que cambia vidas todos los días.
Mejora tus experiencias de juegos: ¿Eres apasionado por los juegos? Empresas como Nintendo o Riot Games siempre están en busca de talentos que puedan hacer que los juegos sean aún más emocionantes. Eso podrías ser tú.
Transforma el envío y los viajes: Imagina ayudar a FedEx o a Delta Airlines a mover cosas de manera más rápida e inteligente alrededor del mundo.
Dale forma al futuro con la IA: ¿Sueñas con trabajar con IA generativa? Tu comprensión de las estructuras de datos es crucial. Podrías ser parte de un trabajo innovador en lugares como OpenAI, Google, Netflix, Tesla o SpaceX, convirtiendo lo que antes era ciencia ficción en realidad.
Al completar este viaje, tu comprensión de las estructuras de datos se extenderá mucho más allá de la mera comprensión. Estarás preparado para aplicarlas de manera efectiva.
Imagina mejorar el rendimiento de la aplicación, idear soluciones para desafíos empresariales o incluso desempeñar un papel en avances tecnológicos pioneros. Tus nuevas habilidades abrirán puertas a diversas oportunidades, posicionándote como solucionador de problemas de referencia.
Paisaje urbano digital abstracto con estructuras cúbicas interconectadas y líneas brillantes que simbolizan estructuras de datos complejas – Fuente: lunartech.ai
1. La Importancia de las Estructuras de Datos
Aprender sobre estructuras de datos puede realmente ayudarte a mejorar tus habilidades de ingeniería de software. Estos componentes críticos son clave para garantizar que tus aplicaciones funcionen sin problemas, lo cual es una habilidad imprescindible para todo ingeniero de software.
Mejoran la Eficiencia y el Rendimiento
Las estructuras de datos son los turbo cargadores de tu código. Hacen más que solo almacenar datos: permiten un acceso rápido y eficiente. Imagina una tabla hash como tu herramienta de acceso instantáneo para una recuperación rápida de datos o una lista enlazada como tu estrategia dinámica y adaptable para las necesidades de datos en constante evolución.
Optimizan el Uso y la Gestión de la Memoria
Estas estructuras son realmente buenas para optimizar la memoria. Ajustan finamente el consumo de memoria de tu programa, asegurando la robustez bajo cargas de datos pesadas y ayudándote a evitar problemas comunes como las fugas de memoria.
Impulsan la Resolución de Problemas y el Diseño de Algoritmos
Las estructuras de datos elevan tu código de funcional a excepcional. Organizan eficientemente los datos y las operaciones, mejorando la efectividad, la reutilización y la escalabilidad de tu código. Esto resulta en una mejor mantenibilidad y adaptabilidad de tu software.
Son Esenciales para el Avance Profesional
Comprender las estructuras de datos es crucial para cualquier aspirante a ingeniero de software. No solo proporcionan formas eficientes de manejar datos y mejorar el rendimiento, sino que también son fundamentales para resolver problemas complejos y diseñar algoritmos.
Estas habilidades son vitales para el crecimiento profesional, especialmente para aquellos que aspiran a ocupar cargos técnicos superiores. Gigantes de la tecnología como Google, Amazon y Microsoft valoran mucho esta experiencia.
Conclusión
Aprender a fondo las estructuras de datos puede ayudarte a destacar en entrevistas técnicas y a atraer a los principales empleadores. También las utilizarás todos los días como desarrollador.
Las estructuras de datos son fundamentales para construir sistemas escalables y abordar problemas de programación complejos, y son clave para mantener una ventaja competitiva en el sector tecnológico en constante evolución.
Esta guía se centra en estructuras de datos cruciales, capacitándote para crear soluciones de software eficientes y avanzadas. Comienza tu viaje para mejorar tus capacidades técnicas para los desafíos futuros de la industria.
Paisaje urbano geométrico complejo que ilustra estructuras de datos, con edificios cúbicos interconectados por senderos brillantes y nodos resaltados con luminiscencia, que simbolizan sistemas organizativos – Fuente: lunartech.ai
2. Tipos de Estructuras de Datos
Las estructuras de datos son herramientas esenciales en el desarrollo de software que permiten el almacenamiento, la organización y la manipulación eficientes de datos. Comprender los diferentes tipos de estructuras de datos es crucial para los aspirantes a ingenieros de software, ya que les ayuda a elegir la estructura más adecuada para sus necesidades específicas.
Sumergámonos en algunos de los tipos de estructuras de datos más comúnmente utilizados:
Arrays: El Pilar de la Gestión Eficiente de Datos
Los arrays, la piedra angular de las estructuras de datos, personifican la eficiencia al almacenar elementos del mismo tipo en ranuras de memoria contiguas. Su poder radica en su capacidad para ofrecer un acceso directo y ultrarrápido a cualquier elemento, simplemente conociendo su índice.
Esta característica, según un estudio de la Universidad de Stanford, hace que los arrays sean hasta un 30% más rápidos para el acceso aleatorio en comparación con otras estructuras.
Pero los arrays tienen sus limitaciones: su tamaño es fijo y modificar su longitud, especialmente para arrays grandes, puede ser una tarea intensiva en recursos.
Visión Práctica: Considera usar int[] numeros = {1, 2, 3, 4, 5}; para escenarios donde el acceso rápido y aleatorio es fundamental y las modificaciones de tamaño son mínimas.
Listas enlazadas: Flexibilidad en su máxima expresión
Las listas enlazadas destacan en escenarios que requieren asignación dinámica de memoria. A diferencia de los arreglos, no requieren memoria contigua, lo que las hace más flexibles si necesitas cambiar su tamaño. Esto las hace ideales para aplicaciones en las que el volumen de datos puede fluctuar significativamente.
Pero su flexibilidad tiene un costo: según los hallazgos del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT, recorrer una lista enlazada puede ser hasta un 20% más lento que acceder a elementos en un arreglo debido al acceso secuencial.
Ilustración de una lista enlazada. Fuente: lunartech.ai
Visión práctica: Utiliza 1 -> 2 -> 3 -> 4 -> 5 para datos que requieren inserciones y eliminaciones frecuentes.
Stacks: Simplificando operaciones de último en entrar, primero en salir
Las stacks siguen el principio de último en entrar, primero en salir (LIFO). Este único punto de acceso en la parte superior simplifica la adición y eliminación de elementos, lo que las hace una excelente opción para aplicaciones como pilas de llamadas a funciones, mecanismos de deshacer y evaluación de expresiones.
El curso CS50 de Harvard sugiere que las stacks son hasta un 50% más eficientes en el manejo de ciertos tipos de tareas de procesamiento de datos secuenciales.
Visión práctica: Implementa stacks [5, 4, 3, 2, 1] (Tope: 5) para invertir secuencias de datos o analizar expresiones.
Colas: Dominando el procesamiento secuencial
Operando según el principio de primero en entrar, primero en salir (FIFO), las colas aseguran que el primer elemento que entra siempre es el primero en salir. Con puntos de acceso distintos en el frente y la parte trasera, las colas ofrecen operaciones simplificadas, lo que las hace indispensables en programación de tareas, gestión de recursos y algoritmos de búsqueda en amplitud.
La investigación indica que las colas pueden mejorar la eficiencia de gestión de procesos hasta en un 40% en sistemas computacionales.
Visión práctica: Opta por colas [1, 2, 3, 4, 5] (Frente: 1, Trasera: 5) en escenarios que requieran procesamiento secuencial, como programación de tareas.
Árboles: Los maestros de los datos jerárquicos
Los árboles, una estructura jerárquica de nodos enlazados por aristas, son incomparables en la representación de datos en capas. El nodo raíz forma la base, con capas subsiguientes que se ramifican. Su naturaleza no lineal permite una organización y recuperación eficientes de datos, especialmente en bases de datos y sistemas de archivos.
Según el IEEE, los árboles pueden mejorar la eficiencia de búsqueda de datos en más de un 60% en sistemas jerárquicos.
Visión práctica: Los árboles se utilizan mejor en escenarios que requieren organización estructurada y jerárquica de datos, como indexación de bases de datos o estructuración de sistemas de archivos.
Gráficos: Mapeo de datos interconectados
Los gráficos son excelentes para ilustrar las relaciones entre varios puntos de datos a través de nodos (vértices) y aristas (conexiones). Sobresalen en aplicaciones que involucran la topología de redes, el análisis de redes sociales y la optimización de rutas.
Los gráficos aportan un nivel de interconexión y flexibilidad que las estructuras de datos lineales no pueden igualar. Según un reciente artículo de la ACM, los algoritmos de gráficos han sido fundamentales para optimizar los diseños de redes, mejorando la eficiencia hasta en un 70%.
Visión práctica: Implementa gráficos para conjuntos de datos complejos donde las relaciones y la interconexión son factores clave.
Tablas hash: Los velocistas de la recuperación de datos
Las tablas hash destacan como el pináculo de la gestión eficiente de datos, aprovechando pares clave-valor para una recuperación de datos ágil. Reconocidas por su velocidad, especialmente en operaciones de búsqueda, las tablas hash, como destaca un informe del IEEE, pueden reducir significativamente el tiempo de acceso a los datos, logrando frecuentemente una complejidad de tiempo constante.
Esta eficiencia se deriva de su mecanismo único de utilizar funciones hash para asignar claves a ranuras específicas, permitiendo un acceso inmediato. Se adaptan dinámicamente a diferentes tamaños de datos, una característica que ha llevado a su uso generalizado en aplicaciones como la indexación y el almacenamiento en caché de bases de datos.
Pero tendrás que enfrentarte al desafío ocasional de las “colisiones”, donde diferentes claves se hashean al mismo índice. Aún así, con funciones hash bien diseñadas, como recomiendan los expertos en algoritmos computacionales, las tablas hash siguen siendo incomparables en equilibrar velocidad y flexibilidad.
Ilustración de una tabla hash. Fuente: lunartech.ai
Visión práctica: Considera usar HashMap<String, Integer> userAges = new HashMap<>(); userAges.put("Alice", 30); userAges.put("Bob", 25); en escenarios que requieran una recuperación rápida y frecuente de datos.
Representación digital de una gran parrilla organizada de rascacielos iluminados, que representa estructuras de datos de matriz, con líneas luminosas que se cruzan entre ellos para denotar conexiones de datos estructurados e indexación. Fuente: lunartech.ai
3. Estructura de datos de matriz
Las matrices son como una fila de casilleros numerados secuencialmente, cada uno conteniendo elementos específicos. Representan una agrupación estructurada de datos, donde cada elemento se almacena en ubicaciones de memoria contiguas. Esta configuración permite un acceso eficiente y directo a cada elemento de datos utilizando un índice numérico.
Las matrices son fundamentales en la programación, sirviendo como base para la organización y manipulación de datos. Su estructura lineal simplifica el concepto de almacenamiento de datos, haciéndolo intuitivo y accesible.
Las matrices son cruciales en diversas tareas computacionales, desde las más básicas hasta las más complejas. Ofrecen una combinación de simplicidad y eficiencia, lo que las hace ideales para numerosas aplicaciones.
¿Qué hace una matriz?
Las matrices almacenan principalmente elementos de datos de un solo tipo en un orden secuencial. Son esenciales para administrar múltiples elementos de manera colectiva y sistemática. Las matrices facilitan la indexación eficiente, que es fundamental para manejar conjuntos de datos grandes.
Esta estructura de datos es crucial para algoritmos que requieren un acceso rápido a los elementos. Las matrices agilizan tareas como la clasificación, la búsqueda y el almacenamiento de datos homogéneos. Su importancia en la gestión de datos no puede ser subestimada, especialmente en campos como la gestión de bases de datos y el desarrollo de software.
Las matrices, gracias a su estructura, ofrecen un formato predecible y fácil de entender para el almacenamiento de datos.
¿Cómo funcionan las matrices?
Las matrices almacenan datos en ubicaciones de memoria adyacentes, garantizando continuidad y acceso rápido. Cada elemento en una matriz es como un compartimento en una fila de unidades de almacenamiento, cada uno marcado con un índice. Esta indización comienza desde cero, lo que permite un acceso directo y predecible a cada elemento.
Las matrices pueden utilizar eficientemente la memoria, ya que almacenan elementos del mismo tipo de forma contigua. La asignación lineal de memoria de las matrices las convierte en una opción preferida para necesidades de almacenamiento de datos sencillo. Acceder a un elemento de matriz es similar a seleccionar un libro de una estantería numerada. Este mecanismo simple pero efectivo es lo que hace que las matrices sean tan ampliamente utilizadas.
Operaciones clave en arrays
Las operaciones fundamentales realizadas en los arrays son: acceder a los elementos, insertar elementos, eliminar elementos, recorrer el array, buscar en el array, y actualizar el array.
Explicación de cada operación:
Acceder a los elementos implica identificar y recuperar un elemento a partir de un índice específico.
Insertar elementos es el proceso de agregar un nuevo elemento en un índice deseado dentro del array.
Eliminar elementos se refiere a la eliminación de un elemento, seguida del ajuste de los elementos restantes.
Recorrer un array significa recorrer sistemáticamente cada elemento, generalmente para inspección o modificación.
Buscar en un array tiene como objetivo localizar un elemento específico dentro del array.
Actualizar un array es la acción de modificar el valor de un elemento existente en un índice determinado.
Ejemplo de código de array en Java
Veamos un ejemplo de cómo trabajar con un array en Java:
public class ArrayOperations { public static void main(String[] args) { int[] array = {10, 20, 30, 40, 50}; // Operación de acceso int primerElemento = array[0]; System.out.println("Operación de acceso: Primer elemento = " + primerElemento); // Salida esperada: "Operación de acceso: Primer elemento = 10" // Operación de inserción (para mayor simplicidad, reemplazo de un elemento) array[2] = 35; // Reemplazo del tercer elemento (índice 2) System.out.println("Operación de inserción: Elemento en el índice 2 = " + array[2]); // Salida esperada: "Operación de inserción: Elemento en el índice 2 = 35" // Operación de eliminación (para mayor simplicidad, establecer un elemento en 0) array[3] = 0; // Eliminación del cuarto elemento (índice 3) System.out.println("Operación de eliminación: Elemento en el índice 3 después de la eliminación = " + array[3]); // Salida esperada: "Operación de eliminación: Elemento en el índice 3 después de la eliminación = 0" // Operación de recorrido System.out.println("Operación de recorrido:"); for (int i = 0; i < array.length; i++) { System.out.println("Elemento en el índice " + i + " = " + array[i]); } // Salida esperada para el recorrido: // "Elemento en el índice 0 = 10" // "Elemento en el índice 1 = 20" // "Elemento en el índice 2 = 35" // "Elemento en el índice 3 = 0" // "Elemento en el índice 4 = 50" // Operación de búsqueda para el valor 35 System.out.println("Operación de búsqueda: Búsqueda del valor 35"); for (int i = 0; i < array.length; i++) { if (array[i] == 35) { System.out.println("Valor 35 encontrado en el índice " + i); break; } } // Salida esperada: "Valor 35 encontrado en el índice 2" // Operación de actualización array[1] = 25; // Actualización del segundo elemento (índice 1) System.out.println("Operación de actualización: Elemento en el índice 1 después de la actualización = " + array[1]); // Salida esperada: "Operación de actualización: Elemento en el índice 1 después de la actualización = 25" // Estado final del array después de todas las operaciones System.out.println("Estado final del array:"); for (int valor : array) { System.out.println(valor); } // Salida esperada para el estado final: // "10" // "25" // "35" // "0" // "50" }}
¿Cuándo debes usar arrays?
Los arrays son útiles en diversos escenarios donde se requiere almacenamiento organizado de datos. Son perfectos para manejar listas de elementos como nombres, números o identificadores.
Los arrays se utilizan extensivamente en aplicaciones de software como hojas de cálculo y sistemas de bases de datos. Su estructura predecible los hace ideales para situaciones que requieren acceso rápido a los datos. También se utilizan comúnmente en algoritmos de ordenación y búsqueda.
Los arrays pueden ser particularmente útiles en aplicaciones donde conoces el tamaño del conjunto de datos de antemano. Los arrays sirven de base para estructuras de datos más complejas, por lo que es esencial que los comprendas como desarrollador.
Ventajas y limitaciones de los arrays
Los arrays ofrecen un acceso rápido a los elementos, resultado de su asignación de memoria contigua. Su simplicidad y facilidad de uso los convierten en una elección popular en programación. Los arrays también proporcionan un patrón predecible de uso de memoria, mejorando la eficiencia.
Pero los arrays tienen un tamaño fijo, lo que limita su flexibilidad. Este tamaño fijo puede llevar a un desperdicio de espacio o a problemas de capacidad insuficiente. La inserción y eliminación de elementos en los arrays puede ser ineficiente, ya que a menudo requieren desplazar elementos.
A pesar de estas limitaciones, los arrays son una herramienta fundamental en el kit de herramientas de un programador, equilibrando la simplicidad y la funcionalidad.
Puntos clave
Los arrays son una estructura de datos principal para el almacenamiento organizado y secuencial de datos. Su capacidad para almacenar y gestionar colecciones de datos de manera eficiente es incomparable en muchos escenarios.
Los arrays son fundamentales en la programación, formando la base de estructuras y algoritmos más complejos. Comprender los arrays es esencial para cualquier persona que se adentre en el desarrollo de software o el procesamiento de datos.
El dominio de los arrays dota a los programadores de una herramienta vital para la gestión eficiente de datos. Los arrays, en esencia, son los bloques de construcción de muchas soluciones de programación sofisticadas.
Visualización futurista de una Estructura de Datos Lista Enlazada Simple, con nodos iluminados conectados en una secuencia lineal mediante caminos brillantes dirigidos, resaltando el flujo de navegación unidireccional de los datos. – Fuente: lunartech.ai`
4. Estructura de Datos de Lista Enlazada Simple
Imagina una lista enlazada simple como una secuencia de vagones de tren conectados en línea, donde cada vagón es un elemento de datos individual.
Una lista enlazada es una colección secuencial y dinámica de elementos llamados nodos. Cada nodo apunta a su sucesor, estableciendo una estructura en forma de cadena y navegable. Esta configuración permite una organización lineal pero adaptable de los datos.
¿Qué hace una lista enlazada?
La funcionalidad principal de una lista enlazada es su disposición de datos secuencial. Cada nodo, que contiene datos y una referencia al siguiente nodo, agiliza operaciones como inserciones y eliminaciones, ofreciendo un sistema de gestión de datos altamente eficiente.
En el diverso mundo de las estructuras de datos, las listas enlazadas destacan por su adaptabilidad. Son particularmente valiosas en escenarios donde el volumen de datos varía dinámicamente, lo que las convierte en una solución flexible para las necesidades informáticas modernas.
¿Cómo funcionan las listas enlazadas?
La estructura de una lista enlazada se construye sobre nodos. Cada nodo consta de dos partes: los propios datos y un puntero al siguiente nodo.
Imagina una búsqueda del tesoro. Cada pista (nodo) te guía no solo a un tesoro (dato) sino también a la siguiente pista (siguiente nodo).
Operaciones clave de las listas enlazadas
Las operaciones fundamentales en una lista enlazada incluyen agregar nodos, eliminar nodos, encontrar nodos, iterar a través de la lista y actualizar la lista.
Agregar nodos implica insertar un nuevo nodo en la lista.
Eliminar nodos se centra en eliminar de manera eficiente un nodo de la lista.
Encontrar nodos tiene como objetivo localizar un nodo específico recorriendo la lista.
Iterar a través de una lista implica moverse de forma secuencial a través de cada nodo de la lista.
Actualizar una lista permite modificar los datos dentro de un nodo existente.
¿Cuándo se utilizan las listas enlazadas?
Las listas enlazadas destacan en entornos donde se insertan o eliminan datos con frecuencia. Su versatilidad se extiende desde impulsar funcionalidades de deshacer en software hasta permitir la gestión de memoria dinámica en sistemas operativos.
Ventajas y limitaciones de las listas enlazadas
La principal ventaja de las listas enlazadas radica en su flexibilidad de tamaño y eficiencia en las inserciones y eliminaciones.
Pero tienen un mayor uso de memoria debido al almacenamiento de referencias y no ofrecen acceso directo a los elementos, dependiendo de la búsqueda secuencial.
Demostración de código de la lista enlazada
Veamos un ejemplo de problema que utiliza una lista enlazada: la gestión de una lista de tareas dinámica.
import java.util.LinkedList;public class LinkedListOperations { public static void main(String[] args) { LinkedList<String> list = new LinkedList<>(); // Operación de Agregar list.add("Nodo1"); System.out.println("Después de agregar Nodo1: " + list); // Salida esperada: [Nodo1] list.add("Nodo2"); System.out.println("Después de agregar Nodo2: " + list); // Salida esperada: [Nodo1, Nodo2] list.add("Nodo3"); System.out.println("Después de agregar Nodo3: " + list); // Salida esperada: [Nodo1, Nodo2, Nodo3] // Operación de Eliminar list.remove("Nodo2"); System.out.println("Después de eliminar Nodo2: " + list); // Salida esperada: [Nodo1, Nodo3] // Operación de Encontrar boolean encontrado = list.contains("Nodo3"); System.out.println("Operación de Encontrar - ¿Está Node3 en la lista? " + encontrado); // Salida esperada: true // Operación de Iterar System.out.print("Operación de Iterar: "); for(String nodo : list) { System.out.print(nodo + " "); // Salida esperada: Nodo1 Nodo3 } System.out.println(); // Operación de Actualizar list.set(0, "NuevoNodo1"); System.out.println("Después de actualizar Nodo1 a NuevoNodo1: " + list); // Salida esperada: [NuevoNodo1, Nodo3] // Estado final de la lista System.out.println("Estado final de la lista: " + list); // Salida esperada: [NuevoNodo1, Nodo3] }}
Conclusiones clave
Las listas enlazadas son una estructura de datos dinámica esencial que es fundamental para la gestión efectiva y adaptable de los datos. Dominar las listas enlazadas es vital para todos los desarrolladores, ya que ofrecen una combinación única de simplicidad, flexibilidad y profundidad funcional.
Visualización iluminada de una estructura de datos de lista enlazada doble con nodos que presentan conexiones bidireccionales, mostrando las capacidades de recorrido hacia adelante y hacia atrás dentro de la estructura. – Fuente: lunartech.ai
5. Estructura de datos de lista enlazada doble
La lista enlazada doble es una evolución en estructuras de datos. Es como una calle de doble sentido donde cada nodo sirve como una casa con puertas que conducen a las casas vecinas, tanto a la siguiente como a la anterior.
A diferencia de su pariente de lista enlazada simple, esta estructura le brinda a los nodos el lujo de conocer tanto a su predecesor como a su sucesor, una característica que cambia fundamentalmente cómo se pueden recorrer y manipular los datos.
Las listas enlazadas dobles son una forma más detallada y versátil de manejar datos, reflejando la complejidad y la interconexión de los escenarios del mundo real.
¿Qué hace una lista enlazada doble?
Las listas enlazadas dobles son las multitareas del mundo de las estructuras de datos, expertas en navegación de datos hacia adelante y hacia atrás. Sobresalen en aplicaciones donde la flexibilidad en el movimiento a través de los datos es primordial.
Esta estructura permite a los usuarios avanzar y retroceder entre elementos con facilidad, una característica particularmente invaluable en secuencias de datos complejas donde tanto los elementos pasados como los futuros pueden necesitar referencias rápidas.
¿Cómo funcionan las listas enlazadas dobles?
Cada nodo en una lista enlazada doble es una unidad autocontenida con tres componentes clave: los datos que almacena, un puntero al siguiente nodo y un puntero al nodo anterior.
Esta configuración es algo similar a una lista de reproducción donde cada canción (nodo) conoce tanto la canción anterior como la siguiente, lo que permite una transición fluida en ambas direcciones. La lista forma así un camino bidireccional a través de sus elementos, lo que la hace inherentemente más flexible que una lista enlazada simple.
Operaciones clave en listas enlazadas dobles
Las operaciones clave en una lista enlazada doble incluyen agregar, eliminar, encontrar, iterar (tanto hacia adelante como hacia atrás) y actualizar nodos.
Agregar implica insertar nuevos elementos en posiciones precisas.
Eliminar significa desvincular y eliminar un nodo de la lista.
Encontrar nodos es más eficiente, ya que se puede comenzar desde cualquier extremo.
La iteración es especialmente versátil, permitiendo recorrer en ambas direcciones.
Actualizar nodos implica modificar datos existentes, similar a revisar entradas en un libro de registro.
¿Cuándo se utilizan las listas enlazadas dobles?
Las listas enlazadas dobles encuentran utilidad en sistemas donde la navegación bidireccional es beneficiosa.
Se utilizan en historiales de navegadores, permitiendo a los usuarios moverse hacia adelante y hacia atrás a través de los sitios visitados anteriormente. En aplicaciones como reproductores de música o visores de documentos, permiten a los usuarios moverse entre elementos de manera fluida e intuitiva. Su capacidad para insertar y eliminar elementos de manera eficiente también los hace adecuados para tareas de manipulación de datos dinámicos.
Ventajas y limitaciones de las listas enlazadas dobles
La lista enlazada doble destaca por su capacidad para recorrer hacia adelante y hacia atrás, ofreciendo un nivel de manipulación de elementos que las listas enlazadas simples no pueden igualar. Esta capacidad única permite recorrer los datos tanto hacia adelante como hacia atrás con igual eficiencia, mejorando significativamente las posibilidades algorítmicas en estructuras de datos complejas.
Pero esta funcionalidad avanzada exige un intercambio: cada nodo requiere dos punteros (al nodo anterior y al siguiente), lo que resulta en un mayor consumo de memoria.
Además, las listas enlazadas dobles son más complejas de implementar en comparación con las listas enlazadas simples. Esto puede plantear desafíos en términos de mantenimiento y comprensión del código para principiantes.
A pesar de estas consideraciones, la lista enlazada doble sigue siendo una elección sólida para escenarios de datos dinámicos donde los beneficios de su estructura flexible superan el costo de memoria adicional y complejidad.
Ejemplo de código de lista enlazada doble
class Nodo {
String datos;
Nodo siguiente;
Nodo anterior;
Nodo(String datos) {
this.datos = datos;
}
}
class ListaEnlazadaDoble {
Nodo cabeza;
Nodo cola;
// Método para agregar un nodo al final de la lista
void agregar(String datos) {
Nodo nuevoNodo = new Nodo(datos);
if (cabeza == null) {
cabeza = nuevoNodo;
cola = nuevoNodo;
} else {
cola.siguiente = nuevoNodo;
nuevoNodo.anterior = cola;
cola = nuevoNodo;
}
}
// Método para eliminar un nodo específico
boolean eliminar(String datos) {
Nodo actual = cabeza;
while (actual != null) {
if (actual.datos.equals(datos)) {
if (actual.anterior != null) {
actual.anterior.siguiente = actual.siguiente;
} else {
cabeza = actual.siguiente;
}
if (actual.siguiente != null) {
actual.siguiente.anterior = actual.anterior;
} else {
cola = actual.anterior;
}
return true;
}
actual = actual.siguiente;
}
return false;
}
// Método para encontrar un nodo
boolean contiene(String datos) {
Nodo actual = cabeza;
while (actual != null) {
if (actual.datos.equals(datos)) {
return true;
}
actual = actual.siguiente;
}
return false;
}
// Método para imprimir la lista de cabeza a cola
void imprimirAdelante() {
Nodo actual = cabeza;
while (actual != null) {
System.out.print(actual.datos + " ");
actual = actual.siguiente;
}
System.out.println();
}
// Método para imprimir la lista de cola a cabeza
void imprimirAtras() {
Nodo actual = cola;
while (actual != null) {
System.out.print(actual.datos + " ");
actual = actual.anterior;
}
System.out.println();
}
// Método para actualizar los datos de un nodo
boolean actualizar(String datosAntiguos, String nuevosDatos) {
Nodo actual = cabeza;
while (actual != null) {
if (actual.datos.equals(datosAntiguos)) {
actual.datos = nuevosDatos;
return true;
}
actual = actual.siguiente;
}
return false;
}
}
public class OperacionesListaEnlazadaDoble {
public static void main(String[] args) {
ListaEnlazadaDoble lista = new ListaEnlazadaDoble();
// Operación de agregar
lista.agregar("Nodo1");
lista.agregar("Nodo2");
lista.agregar("Nodo3");
System.out.println("Después de las operaciones de agregar:");
lista.imprimirAdelante(); // Resultado esperado: Nodo1 Nodo2 Nodo3
// Operación de eliminar
lista.eliminar("Nodo2");
System.out.println("Después de la operación de eliminar:");
lista.imprimirAdelante(); // Resultado esperado: Nodo1 Nodo3
// Operación de encontrar
boolean seEncontroNodo1 = lista.contiene("Nodo1");
boolean seEncontroNodo3 = lista.contiene("Nodo3");
System.out.println("Operación de encontrar - ¿Se encuentra el Nodo1 en la lista? " + seEncontroNodo1); // Resultado
Aplicaciones del mundo real de las listas doblemente enlazadas
Las listas doblemente enlazadas son especialmente útiles en aplicaciones que requieren la inserción y eliminación frecuente y eficiente de elementos desde ambos extremos de la lista.
Se utilizan ampliamente en sistemas informáticos avanzados como aplicaciones de juegos, donde las acciones de los jugadores pueden dictar cambios inmediatos en el estado del juego, o en sistemas de navegación dentro de software complejo, permitiendo a los usuarios recorrer estados o configuraciones históricas.
Otra aplicación clave está en software multimedia, como herramientas de edición de fotos o videos, donde un usuario puede necesitar moverse hacia adelante y hacia atrás a través de una secuencia de ediciones.
Su capacidad de recorrido bidireccional también las hace ideales para implementar algoritmos avanzados en políticas de eliminación de caché utilizadas en sistemas de administración de bases de datos, donde el orden de los elementos necesita modificarse con frecuencia y eficiencia.
Aspectos de rendimiento de las listas doblemente enlazadas
En términos de rendimiento, las listas doblemente enlazadas ofrecen ventajas significativas, así como algunos compromisos en comparación con otras estructuras de datos.
La complejidad temporal para las operaciones de inserción y eliminación en ambos extremos de la lista es O(1), lo que hace que estas operaciones sean extremadamente eficientes. Pero buscar un elemento en una lista doblemente enlazada tiene una complejidad temporal de O(n), ya que puede requerir recorrer la lista. Esto es menos eficiente en comparación con estructuras de datos como las tablas hash.
Además, el espacio adicional de memoria para almacenar dos punteros para cada nodo es algo a considerar en aplicaciones sensibles a la memoria. Esto contrasta con los arrays y las listas simplemente enlazadas, donde el uso de memoria suele ser menor.
Aun así, para aplicaciones donde la inserción y eliminación rápidas son críticas, y el tamaño del conjunto de datos no es abrumadoramente grande, las listas doblemente enlazadas ofrecen una combinación equilibrada de eficiencia y flexibilidad.
Puntos clave
En esencia, las listas doblemente enlazadas representan un enfoque sofisticado para la gestión de datos, ofreciendo flexibilidad y eficiencia mejoradas. Y querrás entenderlas a medida que te adentres en implementaciones de estructuras de datos más avanzadas.
Las listas doblemente enlazadas sirven como puente entre la gestión básica de datos y las necesidades de manipulación de datos más complejas. Esto las convierte en un componente vital en el conjunto de herramientas de un programador para soluciones de datos sofisticadas.
Una estructura vertical y en capas que brilla con haces de luz dorada, representando el concepto Last In, First Out (LIFO) de una estructura de datos de pila, con la capa superior brillantemente iluminada para significar la parte superior de la pila. - Fuente: lunartech.ai
6. Estructura de datos de pila
Imagina una pila como una torre de platos de una cafetería, donde la única forma de interactuar con ellos es agregando o quitando un plato de la parte superior.
Una pila, en el mundo de las estructuras de datos, es una colección lineal y ordenada de elementos que sigue estrictamente el principio LIFO (Last In, First Out). Esto significa que el último elemento agregado es el primero en ser eliminado. Si bien esto puede sonar simplista, sus implicaciones para la gestión de datos son profundas y de gran alcance.
Las pilas sirven como un concepto fundamental en la ciencia de la computación, formando la base para muchos algoritmos y funcionalidades complejas. En esta sección, exploraremos las pilas en profundidad, descubriendo sus aplicaciones, operaciones y significado en la informática moderna.
¿Qué hace una pila?
El propósito fundamental de una pila es almacenar elementos de manera ordenada y reversible. Las operaciones principales son agregar (push) y quitar (pop) desde la parte superior de la pila. Esta estructura aparentemente simple tiene una importancia inmensa en escenarios donde el acceso inmediato a los datos agregados más recientemente es crítico.
Consideremos algunos escenarios en los que las pilas son indispensables. En el desarrollo de software, los mecanismos de deshacer en editores de texto dependen de pilas para almacenar el historial de cambios. Cuando presionas "Deshacer escritura", estás quitando elementos de la parte superior de la pila, revirtiendo estados anteriores.
De manera similar, navegar por el historial de tu navegador web, haciendo clic en "Atrás" o "Adelante", utiliza una estructura basada en pilas para gestionar las páginas que has visitado.
¿Cómo funcionan las pilas?
Para entender cómo funcionan las pilas, usemos una analogía práctica: imagina una pila de libros. En esta pila, solo puedes interactuar con los libros en la parte superior. Puedes agregar un nuevo libro a la pila, que se convierte en el libro más superior, o puedes quitar el libro superior. Esto resulta en un orden secuencial de libros que refleja el principio LIFO.
Si quieres acceder a un libro desde el medio o la parte inferior de la pila, primero debes quitar todos los libros que estén encima. Esta característica central simplifica la gestión de datos en varias aplicaciones, asegurando que el elemento más recientemente agregado siempre sea el siguiente en procesarse.
Operaciones Clave de la Pila
Las operaciones clave en una pila son los bloques de construcción de su funcionalidad. Veamos cada operación en detalle:
Push agrega un elemento en la parte superior de la pila. Es como colocar un plato nuevo en la parte superior de la pila en nuestra analogía de la cafetería.
Pop elimina y devuelve el elemento superior de la pila. Es como tomar el plato más arriba de la pila.
Peek te permite ver el elemento superior sin quitarlo. Puedes pensar en esto como echar un vistazo al plato superior sin quitarlo.
IsEmpty verifica si la pila está vacía. Es esencial verificar si quedan platos en nuestra pila de la cafetería.
Search te ayuda a encontrar la posición de un elemento específico dentro de la pila. Te dice qué tan abajo en la pila se encuentra un elemento.
Estas operaciones son las herramientas que los desarrolladores utilizan para manipular datos dentro de una pila, asegurando que se mantenga ordenada y eficiente.
¿Cuándo se Usan las Pilas?
Las pilas encuentran aplicaciones en una amplia variedad de escenarios. Algunos casos de uso comunes incluyen:
Funciones de Deshacer: En editores de texto y otros software, se utilizan pilas para implementar funcionalidades de deshacer/rehacer, permitiendo a los usuarios volver a estados anteriores.
Historial de Navegador: Cuando navegas hacia atrás o adelante en tu navegador web, en realidad estás recorriendo una pila de páginas visitadas.
Algoritmos de Retroceso: En campos como la inteligencia artificial y la exploración de gráficos, las pilas juegan un papel fundamental en los algoritmos de retroceso, permitiendo una exploración eficiente de las rutas potenciales.
Gestión de Llamadas a Funciones: Cuando llamas a una función en un programa, se agrega un marco de pila a la pila de llamadas, facilitando el seguimiento de las llamadas a funciones y sus valores de retorno.
Estos ejemplos destacan la ubicuidad de las pilas en la informática moderna, convirtiéndolas en un concepto fundamental para los desarrolladores de software.
Ventajas y Limitaciones de las Pilas
Las pilas tienen sus propias fortalezas y limitaciones.
Fortalezas:
Simplicidad: Las pilas son fáciles de implementar y usar.
Eficiencia: Proporcionan una forma eficiente de manejar datos en orden LIFO.
Predictibilidad: El estricto orden LIFO simplifica la gestión de datos y asegura una secuencia clara de operaciones.
Limitaciones:
Acceso Limitado: Las pilas ofrecen un acceso limitado, ya que solo puedes interactuar con el elemento superior. Esto restringe su uso en escenarios que requieren acceso a elementos más profundos dentro de la pila.
Limitaciones de Memoria: Las pilas pueden quedarse sin memoria si se empujan hasta sus límites, lo que puede provocar un error de OutOfMemory. Esto es una preocupación práctica en el desarrollo de software.
A pesar de sus limitaciones, las pilas siguen siendo una herramienta esencial en el arsenal del programador debido a su eficiencia y predictibilidad.
Ejemplo de Código de una Pila
import java.util.Stack;public class AdvancedStackOperations { public static void main(String[] args) { // Crea una pila para almacenar enteros Stack<Integer> pila = new Stack<>(); // Verifica si la pila está vacía boolean estaVacia = pila.isEmpty(); System.out.println("¿Está vacía la pila? " + estaVacia); // Salida: ¿Está vacía la pila? verdadero // Agrega enteros a la pila pila.push(10); pila.push(20); pila.push(30); pila.push(40); pila.push(50); // Muestra la pila después de agregar enteros System.out.println("Pila después de agregar enteros: " + pila); // Salida: Pila después de agregar enteros: [10, 20, 30, 40, 50] // Verifica si la pila está vacía nuevamente estaVacia = pila.isEmpty(); System.out.println("¿Está vacía la pila? " + estaVacia); // Salida: ¿Está vacía la pila? falso // Echa un vistazo al entero en la parte superior sin quitarlo int elementoSuperior = pila.peek(); System.out.println("Vistazo al entero en la parte superior: " + elementoSuperior); // Salida: Vistazo al entero en la parte superior: 50 // Quita el entero en la parte superior de la pila int elementoEliminado = pila.pop(); System.out.println("Entero eliminado: " + elementoEliminado); // Salida: Entero eliminado: 50 // Muestra la pila después de eliminar un entero System.out.println("Pila después de eliminar un entero: " + pila); // Salida: Pila después de eliminar un entero: [10, 20, 30, 40] // Busca un entero en la pila int elementoBuscado = 30; int posicion = pila.search(elementoBuscado); if (posicion != -1) { System.out.println("Posición de " + elementoBuscado + " en la pila (índice basado en 1): " + posicion); } else { System.out.println(elementoBuscado + " no se encontró en la pila."); } // Salida: Posición de 30 en la pila (índice basado en 1): 3 }}
Aplicaciones del mundo real de las pilas
Las estructuras de datos tipo pila tienen amplias aplicaciones en el mundo real, especialmente en informática y desarrollo de software.
Se utilizan comúnmente para implementar funciones de deshacer y rehacer en editores de texto y software de diseño, lo que permite a los usuarios revertir o rehacer acciones de manera eficiente.
En los navegadores web, las pilas permiten una navegación sin problemas a través del historial de navegación cuando los usuarios hacen clic en los botones de retroceso o avance.
Los sistemas operativos dependen de las pilas para administrar llamadas a funciones y contextos de ejecución. Los algoritmos de retroceso en la inteligencia artificial, los juegos y los problemas de optimización se benefician de las pilas para realizar un seguimiento de las opciones y retroceder de manera efectiva.
Las arquitecturas basadas en pilas también se utilizan en el análisis y evaluación de expresiones matemáticas, lo que permite cálculos complejos.
Consideraciones de rendimiento para las pilas
Las pilas son conocidas por su eficiencia, con operaciones clave como push, pop, peek y isEmpty con una complejidad temporal constante de O(1), lo que garantiza un acceso rápido al elemento superior.
Pero las pilas tienen limitaciones, ya que ofrecen acceso limitado a elementos más allá del superior. Esto las hace menos adecuadas para la recuperación de elementos más profundos.
Las pilas también pueden consumir memoria significativa en aplicaciones profundamente recursivas, lo que requiere una administración cuidadosa de la memoria. La optimización de la recursividad de cola y los enfoques iterativos son estrategias para mitigar las preocupaciones de memoria de la pila.
En resumen, las estructuras de datos tipo pila proporcionan soluciones eficientes para aplicaciones del mundo real en el desarrollo de software, pero requieren una comprensión de sus limitaciones y un uso prudente de la memoria para un rendimiento óptimo.
Puntos clave
Las pilas son una estructura de datos esencial en la programación, ofreciendo una forma sencilla pero efectiva de gestionar datos siguiendo el principio de último en entrar, primero en salir (LIFO, por sus siglas en inglés). Comprender cómo funcionan las pilas y cómo utilizar sus operaciones clave es vital para los desarrolladores, dado su amplio uso en diversos escenarios de ciencias de la computación y programación.
Ya sea que estés implementando una función de deshacer en un editor de texto o navegando por el historial del navegador web, las pilas son los héroes detrás de escena que lo hacen posible. Dominarlas es un paso fundamental para convertirse en un desarrollador de software competente.
Una línea de figuras silueteadas con un camino iluminado que las atraviesa, representando una estructura de datos de cola, con la iluminación resaltando la secuencia FIFO (primero en entrar, primero en salir) de un extremo a otro. - Fuente: lunartech.ai
7. Estructura de datos de cola
Imagina las colas como el equivalente digital de una línea de personas esperando pacientemente su turno. Al igual que en la vida real, una estructura de datos de cola sigue el principio de "el primero en llegar, es el primero en ser atendido" (FIFO, por sus siglas en inglés). Esto significa que el primer elemento en agregarse a la cola es el primero en ser procesado.
En esencia, una cola es una estructura de datos lineal diseñada para contener elementos en un orden específico, asegurando que el orden de procesamiento sea justo y predecible.
¿Qué hace una cola?
La función principal de una cola es gestionar elementos basándose en el principio de FIFO que acabamos de mencionar. Sirve como una colección ordenada donde el elemento que ha estado esperando por más tiempo es el próximo en ser atendido.
Ahora, podrías preguntarte por qué una cola es tan crucial en el mundo de la informática. La respuesta radica en su importancia para garantizar que las tareas se procesen en un orden específico.
Imagina escenarios donde el orden de procesamiento es importante, como trabajos de impresión en una cola o almacenamiento intermedio de entradas de teclado. Una cola asegura que estas tareas se ejecuten con precisión, evitando el caos y garantizando la equidad.
¿Cómo funcionan las colas?
Para comprender el funcionamiento interno de una cola, desglosemos sus mecanismos básicos utilizando un ejemplo del mundo real.
En una cola, los elementos se agregan a la cola en la parte posterior y se eliminan de la parte frontal. Esta operación sencilla asegura que el elemento que ha estado esperando por más tiempo sea el siguiente en la fila para ser procesado.
Ejemplo simple: El escenario de venta de boletos del cajero
Imagínate como un cajero que vende entradas para un concierto. Tu cola se forma con los clientes que se acercan a tu caja registradora.
Siguiendo el principio de FIFO, el cliente que llegó primero está al frente de la cola, y el que llegó último está en la parte posterior. A medida que atiendes a los clientes en orden, avanzan en la cola hasta que se les ayuda y luego salen.
Operaciones Clave de Colas
Las colas vienen con un conjunto de operaciones clave que las hacen funcionar sin problemas.
Encolar: Piensa en encolar como clientes uniéndose a la fila. El nuevo elemento se coloca al final de la cola, esperando pacientemente su turno para ser atendido.
Desencolar: Desencolar es similar a atender al cliente al frente de la fila. El elemento en la cabeza de la cola se elimina, lo que indica que ha sido procesado y ahora puede salir de la cola.
Aunque estas operaciones pueden parecer sencillas, son la base de la funcionalidad de una cola.
¿Cuándo se utilizan las Colas?
Ahora que comprendes cómo funciona una cola, veamos algunos casos de uso:
Buffer de Teclado: Cuando escribes rápidamente en tu teclado, la computadora utiliza una cola para asegurarse de que los caracteres aparezcan en la pantalla en el mismo orden en que presionaste las teclas.
Colas de Impresión: En la impresión, se utilizan colas para gestionar los trabajos de impresión, asegurando que se completen en el orden en que se iniciaron.
Aplicaciones del Mundo Real
Imagina servicios en línea donde los usuarios envían solicitudes o tareas, como descargar archivos de un sitio web o procesar pedidos en una plataforma de comercio electrónico. Estas solicitudes se manejan típicamente en orden de llegada, al igual que una cola digital.
De manera similar, en un juego en línea multijugador, los jugadores a menudo se unen a la cola de un servidor de juegos antes de entrar al juego, asegurándose de que sean atendidos en el orden en que se unieron.
En estos escenarios digitales, las colas son fundamentales para gestionar y procesar datos o solicitudes de manera eficiente
Código de Ejemplo de Cola
Para comprender realmente el poder de las colas, adentrémonos en un problema práctico de ejemplo.
Imagina que te han encargado implementar un sistema para procesar solicitudes de servicio al cliente en un centro de llamadas. Cada solicitud se le asigna un nivel de prioridad, y necesitas asegurarte de que las solicitudes de alta prioridad se procesen antes que las de baja prioridad.
Para abordar este problema, puedes utilizar una combinación de colas. Crea colas separadas para cada nivel de prioridad y procesa las solicitudes en el orden de su prioridad. Aquí tienes un fragmento de código simplificado en Java para ilustrar este concepto:
Queue<CustomerRequest> highPriorityQueue = new LinkedList<>();Queue<CustomerRequest> mediumPriorityQueue = new LinkedList<>();Queue<CustomerRequest> lowPriorityQueue = new LinkedList<>();// Encolar solicitudes en función de su prioridadhighPriorityQueue.offer(highPriorityRequest);mediumPriorityQueue.offer(mediumPriorityRequest);lowPriorityQueue.offer(lowPriorityRequest);// Procesar solicitudes en orden de prioridadprocessRequests(highPriorityQueue);processRequests(mediumPriorityQueue);processRequests(lowPriorityQueue);
Este código garantiza que las solicitudes de alta prioridad se procesen antes que las de prioridad media y baja, manteniendo la equidad al abordar diferentes niveles de urgencia.
Veamos otro ejemplo de uso de colas en código:
import java.util.LinkedList;import java.util.Queue;public class QueueOperationsExample { public static void main(String[] args) { // Crear una cola utilizando LinkedList Queue<String> queue = new LinkedList<>(); // Encolar: Agregar elementos a la cola queue.offer("Cliente 1"); queue.offer("Cliente 2"); queue.offer("Cliente 3"); // Mostrar la cola después de encolar System.out.println("Cola después de encolar: " + queue); // Salida esperada: Cola después de encolar: [Cliente 1, Cliente 2, Cliente 3] // Desencolar: Eliminar el elemento en la cabeza de la cola String clienteAtendido = queue.poll(); // Mostrar el cliente atendido y la cola actualizada System.out.println("Cliente atendido: " + clienteAtendido); // Salida esperada: Cliente atendido: Cliente 1 System.out.println("Cola después de desencolar: " + queue); // Salida esperada: Cola después de desencolar: [Cliente 2, Cliente 3] // Encolar más clientes queue.offer("Cliente 4"); queue.offer("Cliente 5"); // Mostrar la cola después de encolar más clientes System.out.println("Cola después de encolar más clientes: " + queue); // Salida esperada: Cola después de encolar más clientes: [Cliente 2, Cliente 3, Cliente 4, Cliente 5] // Desencolar otro cliente String clienteAtendido2 = queue.poll(); // Mostrar el cliente atendido y la cola actualizada System.out.println("Cliente atendido: " + clienteAtendido2); // Salida esperada: Cliente atendido: Cliente 2 System.out.println("Cola después de desencolar: " + queue); // Salida esperada: Cola después de desencolar: [Cliente 3, Cliente 4, Cliente 5] }}
Ventajas y Limitaciones de las Colas
Cada estructura de datos tiene sus propias fortalezas y debilidades, y las colas no son una excepción.
Una de las principales fortalezas de una cola es su capacidad para mantener el orden. Garantiza equidad y previsibilidad en el procesamiento de elementos. Cuando el orden es importante, una cola es la estructura de datos ideal.
Pero las colas también tienen limitaciones. Carecen de la capacidad para priorizar elementos según cualquier otro criterio que no sea su hora de llegada. Si necesitas manejar elementos con diferentes prioridades, probablemente necesitarás complementar las colas con otras estructuras de datos o algoritmos.
Conclusiones Clave
La estructura de datos Cola, basada en el principio de "primero en entrar, primero en salir" (FIFO), es vital para mantener el orden. Implica agregar al final (encolar) y remover desde el principio (desencolar).
Las aplicaciones en el mundo real incluyen buffers de teclado y colas de impresión.
Una estructura en forma de árbol radiante con nodos ramificados, que simboliza una estructura de datos de árbol, donde cada conexión brillante representa una relación padre-hijo que converge hacia la raíz luminosa en la base. - Fuente: lunartech.ai
8. Estructura de Datos de Árbol
Imagina un árbol - no cualquier árbol, sino una jerarquía meticulosamente estructurada que puede revolucionar cómo almacenas y accedes a los datos. Esto no es solo un concepto teórico, es una herramienta poderosa utilizada extensamente en ciencias de la computación y varias industrias.
¿Qué Hace un Árbol?
La función principal de la estructura de datos de árbol es organizar los datos en forma jerárquica, creando una estructura que refleja jerarquías del mundo real.
¿Por qué es esto importante, te preguntarás? Considera lo siguiente: es la base de los sistemas de archivos, garantiza una representación eficiente de datos jerárquicos y sobresale en la optimización de operaciones de búsqueda. Si quieres manejar eficientemente datos con estructura jerárquica, la estructura de datos de árbol es tu elección ideal.
¿Cómo Funcionan los Árboles?
Los mecanismos detrás de los árboles son elegantes y simples, pero increíblemente versátiles. Imagina un árbol genealógico, donde cada individuo es un nodo conectado a sus padres.
Los nodos en un árbol están vinculados a través de relaciones padre-hijo, con un único nodo raíz en la parte superior. Así como en un árbol genealógico real, la información fluye desde la raíz hasta las hojas, creando una jerarquía estructurada.
Ya sea organizando archivos en tu computadora o representando la estructura de una empresa, los árboles proporcionan una forma clara y eficiente de manejar datos jerárquicos.
Operaciones Clave de un Árbol
Comprender las operaciones clave de un árbol es esencial para su uso práctico. Estas operaciones incluyen agregar nodos, eliminar nodos y recorrer el árbol. Sumergámonos en cada una de estas operaciones para entender su importancia:
Agregar Nodos
Agregar nodos a un árbol es similar a expandir su jerarquía. Esta operación te permite incorporar nuevos puntos de datos de manera fluida.
Cuando agregas un nodo, estableces una conexión entre un nodo existente (el padre) y el nuevo nodo (el hijo). Esta relación representa la estructura jerárquica de los datos.
Escenarios prácticos para agregar nodos incluyen la inserción de nuevos archivos en un sistema de archivos o la adición de nuevos empleados a un organigrama.
Eliminar Nodos
Eliminar nodos es una operación crucial para mantener la integridad del árbol. Te permite podar ramas o puntos de datos innecesarios.
Cuando eliminas un nodo, cortas su conexión con el árbol, eliminándolo efectivamente y su subestructura. Esta operación es esencial para tareas como eliminar archivos de un sistema de archivos o gestionar la partida de empleados en una jerarquía organizativa.
Recorrer el Árbol
Recorrer el árbol es como navegar a través de sus ramas para acceder a puntos de datos específicos. El recorrido del árbol es vital para obtener información de manera eficiente.
Existen diversas técnicas de recorrido, cada una con sus propios casos de uso:
Recorrido en Orden visita los nodos en orden ascendente y se utiliza comúnmente en árboles de búsqueda binarios para obtener datos en orden.
Recorrido en Preorden procesa el nodo actual antes que sus hijos y es adecuado para copiar una estructura de árbol.
Recorrido en Postorden procesa el nodo actual después de sus hijos y es útil para eliminar un árbol o evaluar expresiones matemáticas.
Las operaciones de recorrido de árbol proporcionan medios prácticos para explorar y trabajar con datos jerárquicos, lo que los hace accesibles y utilizables en diversas aplicaciones.
Al dominar estas operaciones clave, puedes gestionar de manera efectiva las estructuras de datos jerárquicas, lo que convierte a los árboles en una herramienta valiosa en ciencias de la computación e ingeniería de software.
Ya sea que necesites organizar archivos, representar relaciones familiares o optimizar la recuperación de datos, un entendimiento sólido de estas operaciones te capacita para aprovechar todo el potencial de las estructuras de árbol.
Aspectos de rendimiento de los árboles
Ahora, sumerjámonos en el mundo práctico del rendimiento, un aspecto crítico de la estructura de datos de árbol.
El rendimiento se trata de eficiencia, ¿qué tan rápido puedes ejecutar operaciones en un árbol cuando te enfrentas a datos del mundo real?
Vamos a desglosarlo examinando las complejidades de tiempo y espacio de las operaciones comunes en los árboles, incluyendo inserción, eliminación y recorrido.
Complejidades de tiempo y espacio de las operaciones comunes
Inserción: Cuando agregas nuevos datos a un árbol, ¿qué tan rápido puedes hacerlo? La complejidad de tiempo de la inserción varía según el tipo de árbol.
Por ejemplo, en un árbol de búsqueda binario equilibrado, como los árboles AVL o Rojo-Negro, la inserción tiene una complejidad de tiempo de O(log n), donde n es el número de nodos en el árbol.
Pero en un árbol binario desequilibrado, puede ser tan malo como O(n) en el peor de los casos. La complejidad de espacio de la inserción es típicamente O(1) ya que implica agregar un solo nodo.
Eliminación: Eliminar datos de un árbol debería ser un proceso fluido. Al igual que la inserción, la complejidad de tiempo de la eliminación depende del tipo de árbol.
En árboles de búsqueda binarios equilibrados, la eliminación también tiene una complejidad de tiempo de O(log n). Pero en un árbol desequilibrado, puede ser O(n). La complejidad de espacio de la eliminación es O(1).
Recorrido: Recorrer el árbol, ya sea para buscar, recuperar datos o procesarlos en un orden específico, es una operación fundamental. La complejidad de tiempo de los métodos de recorrido puede variar:
Los recorridos en orden, preorden y postorden tienen una complejidad de tiempo de O(n) ya que visitan cada nodo exactamente una vez.
El recorrido por niveles, usando una cola, también tiene una complejidad de tiempo de O(n). La complejidad de espacio de los métodos de recorrido típicamente depende de las estructuras de datos utilizadas durante el recorrido. Por ejemplo, el recorrido por niveles con una cola tiene una complejidad de espacio de O(w), donde w es el ancho máximo (número de nodos en el nivel más ancho) del árbol.
Complejidad de espacio y uso de memoria
Mientras que la complejidad de tiempo se ocupa de la velocidad, la complejidad de espacio aborda el uso de memoria. Los árboles pueden afectar cuánta memoria consume tu aplicación, lo cual es crucial en entornos conscientes de los recursos.
La complejidad de espacio de toda la estructura del árbol depende de su tipo y equilibrio:
En árboles de búsqueda binarios equilibrados (como AVL, Rojo-Negro), la complejidad de espacio es O(n), donde n es el número de nodos.
En árboles B, que se utilizan en bases de datos y sistemas de archivos, la complejidad de espacio puede ser mayor, pero están diseñados para almacenar eficientemente grandes cantidades de datos.
En árboles desequilibrados, la complejidad de espacio también puede ser O(n), lo que los hace menos eficientes en términos de memoria.
Al ahondar en los aspectos prácticos de las complejidades de tiempo y espacio, estarás preparado para tomar decisiones informadas sobre el uso de árboles en tus proyectos.
Ya sea que estés optimizando el almacenamiento de datos, acelerando las búsquedas o asegurando una gestión eficiente de datos, estos conocimientos te guiarán en la implementación efectiva de estructuras de árbol.
Ejemplo de código de árbol
import java.util.LinkedList;import java.util.Queue;// Clase que representa un solo nodo en el árbolclass TreeNode { int value; // Valor del nodo TreeNode left; // Puntero al hijo izquierdo TreeNode right; // Puntero al hijo derecho // Constructor para crear un nuevo nodo con un valor dado public TreeNode(int value) { this.value = value; this.left = null; // Inicializar el hijo izquierdo como nulo this.right = null; // Inicializar el hijo derecho como nulo }}// Clase que representa un árbol de búsqueda binarioclass BinarySearchTree { TreeNode root; // Raíz del árbol de búsqueda binario // Constructor para crear un árbol de búsqueda binario vacío public BinarySearchTree() { this.root = null; // Inicializar la raíz como nula } // Método público para insertar un valor en el árbol de búsqueda binario public void insert(int value) { // Llamar al método privado recursivo para insertar el valor root = insertRecursive(root, value); } // Método privado recursivo para insertar un valor a partir de un nodo dado private TreeNode insertRecursive(TreeNode current, int value) { if (current == null) { // Si el nodo actual es nulo, crear un nuevo nodo con el valor return new TreeNode(value); } // Decidir si insertar en el subárbol izquierdo o derecho if (value current.value) { // Insertar en el subárbol derecho current.right = insertRecursive(current.right, value); } // Devolver el nodo actual return current; } // Método público para recorrido en orden del árbol de búsqueda binario public void inOrderTraversal() { System.out.println("Recorrido en orden:"); // Comenzar el recorrido en orden recursivo desde la raíz inOrderRecursive(root); System.out.println(); // Salida esperada: "20 30 40 50 60 70 80" } // Método privado recursivo para el recorrido en orden private void inOrderRecursive(TreeNode node) { if (node != null) { // Recorrer el subárbol izquierdo, visitar el nodo, luego recorrer el subárbol derecho inOrderRecursive(node.left); System.out.print(node.value + " "); inOrderRecursive(node.right); } } // Método público para recorrido en preorden del árbol de búsqueda binario public void preOrderTraversal() { System.out.println("Recorrido en preorden:"); // Comenzar el recorrido en preorden recursivo desde la raíz preOrderRecursive(root); System.out.println(); // Salida esperada: "50 30 20 40 70 60 80" } // Método privado recursivo para el recorrido en preorden private void preOrderRecursive(TreeNode node) { if (node != null) { // Visitar el nodo, luego recorrer los subárboles izquierdo y derecho System.out.print(node.value + " "); preOrderRecursive(node.left); preOrderRecursive(node.right); } } // Método público para rec
Ventajas y Limitaciones de los Árboles
Entender las fortalezas y debilidades de los árboles es vital. Hay diversas ventajas, como la eficiente recuperación jerárquica de datos. Pero también hay situaciones en las que los árboles pueden no ser la mejor opción, como datos no estructurados.
Es esencial tomar decisiones informadas sobre cuándo y dónde emplear esta poderosa estructura de datos.
Puntos Claves
Los árboles son herramientas prácticas que pueden revolucionar cómo organizas y accedes a datos jerárquicos.
Ya sea que estés construyendo un sistema de archivos o optimizando algoritmos de búsqueda, la Estructura de Datos de Árbol es tu aliado de confianza en el mundo de las estructuras de datos.
Una red compleja de puntos interconectados que ilustran una Estructura de Datos de Grafos sin un claro comienzo o final, resaltando los múltiples caminos y vértices en una formación no lineal similar a una telaraña. - Fuente: lunartech.ai
9. Estructura de Datos de Grafos
La Estructura de Datos de Grafos es un concepto fundamental en ciencias de la computación, similar a una red de nodos y aristas interconectados.
En su esencia, un grafo representa una colección de nodos (o vértices) conectados por aristas - cada nodo potencialmente contiene un dato, y cada arista significa una relación o conexión.
Ahora, exploraremos la esencia de las estructuras de datos de grafos, su funcionalidad y sus aplicaciones en el mundo real.
¿Qué Hace una Estructura de Datos de Grafos?
Los grafos principalmente modelan relaciones y conexiones complicadas entre varias entidades. Tienen diversas aplicaciones como redes sociales, mapas de carreteras y redes de datos.
Al entender los grafos, puedes comprender la estructura subyacente de muchos sistemas complejos en nuestro mundo digital y físico.
¿Cómo Funcionan los Grafos?
Los grafos funcionan a través de nodos conectados por aristas. Considera un ejemplo no técnico: el mapa de carreteras de una ciudad, o una red social. Estos representan grafos donde las conexiones (aristas) entre puntos (nodos) crean una red.
Operaciones Clave en las Estructuras de Datos de Grafos
En las estructuras de datos de grafos, hay algunas operaciones clave que necesitarás conocer para construir, analizar y modificar la red. Estas operaciones incluyen la adición y eliminación de nodos y aristas, así como el análisis de conexiones y relaciones dentro del grafo.
Agregar un Nodo (Vértice) implica insertar un nuevo nodo en el grafo, sirviendo como el paso inicial en la construcción de la estructura del grafo. Es esencial para expandir la red.
Eliminar un Nodo (Vértice) implica eliminar un nodo y sus aristas asociadas, alterando así la configuración del grafo. Es un paso crucial para modificar el diseño y las conexiones del grafo.
Agregar una Arista o establecer una conexión entre dos nodos es fundamental en la construcción del grafo. En grafos no dirigidos, esta conexión es bidireccional, mientras que en grafos dirigidos, la arista es un enlace unidireccional de un nodo a otro.
Eliminar una Arista entre dos nodos es vital para cambiar las relaciones y vías dentro del grafo.
Verificar Adjacencia o determinar si existe una arista directa entre dos nodos es fundamental para entender su adjacencia, revelando conexiones directas dentro del grafo.
Encontrar Vecinos o identificar todos los nodos directamente conectados a un nodo específico es clave para explorar y comprender la estructura del grafo, ya que revela las conexiones inmediatas de cualquier nodo dado.
Recorrido del Grafo utilizando métodos sistemáticos como la Búsqueda en Profundidad (DFS) y la Búsqueda en Anchura (BFS) permite la exploración exhaustiva de todos los nodos en el grafo.
Operaciones de Búsqueda incluyen localizar nodos específicos o determinar caminos entre nodos, a menudo empleando técnicas de recorrido para navegar a través del grafo.
Ejemplo de Código para Operaciones de Grafo
import java.util.*;public class Graph { // Lista de adyacencia para almacenar aristas del grafo private Map<Integer, List> adjList; // Booleano para verificar si el grafo es dirigido private boolean dirigido; // Constructor para inicializar grafo con indicador dirigido/ no dirigido public Graph(boolean dirigido) { this.dirigido = dirigido; adjList = new HashMap(); } // Método para agregar un nuevo nodo al grafo public void addNode(int nodo) { // Inserta el nodo en la lista de adyacencia si aún no está presente adjList.putIfAbsent(nodo, new ArrayList()); } // Método para eliminar un nodo del grafo public void removeNode(int nodo) { // Elimina el nodo de la lista de adyacencia de otros nodos adjList.values().forEach(e -> e.remove(Integer.valueOf(nodo))); // Elimina el nodo del grafo adjList.remove(nodo); } // Método para agregar una arista entre dos nodos public void addEdge(int nodo1, int nodo2) { // Agrega nodo2 a la lista de adyacencia de nodo1 adjList.get(nodo1).add(nodo2); // Si el grafo no es dirigido, agrega nodo1 a la lista de adyacencia de nodo2
¿Cuándo se utiliza la Estructura de Datos Grafo?
Los grafos se utilizan en escenarios como la modelización de redes sociales, relaciones de base de datos y problemas de enrutamiento. Sus aplicaciones en el mundo real son vastas, lo que subraya su relevancia en diversas industrias y en la vida cotidiana.
Comprender cuándo y cómo utilizar grafos puede mejorar significativamente tus habilidades para resolver problemas en numerosos dominios.
Ventajas y Limitaciones de los Grafos
Los grafos son excelentes para mostrar cómo están conectadas las cosas, lo cual es realmente útil. Pero a veces, no son la mejor opción, especialmente cuando otras estructuras de datos podrían hacer el trabajo más rápido o con menos complicaciones.
Cuando estés decidiendo si usar grafos, piensa en lo que estás intentando hacer. Si las cosas están realmente interconectadas, los grafos podrían ser lo que necesitas. Pero si tus datos son simples y lineales, es posible que desees utilizar algo más fácil de manejar. Elige de forma inteligente para que tu trabajo brille.
Ejemplo de Código Práctico
Un problema clásico del mundo real que se puede resolver de manera efectiva utilizando una estructura de datos de grafo es encontrar el camino más corto en una red. Esto se ve comúnmente en aplicaciones como la planificación de rutas para sistemas de GPS. El problema implica encontrar la ruta más corta desde un punto de partida hasta un punto de destino en una red de calles (o nodos).
Para ilustrar esto, utilizaremos el algoritmo de Dijkstra, que es un método popular para encontrar el camino más corto en un grafo con pesos de borde no negativos. Aquí hay una implementación en Java de este algoritmo junto con una configuración simple del grafo para demostrar el concepto:
import java.util.*;public class Graph { // HashMap para almacenar la lista de adyacencia del grafo private final Map<Integer, List<Node>> adjList = new HashMap<>(); // Clase estática que representa un nodo en el grafo static class Node implements Comparable<Node> { int node; // Identificador del nodo int weight; // Peso de la arista a este nodo // Constructor para Node Node(int node, int weight) { this.node = node; this.weight = weight; } // Sobrescribiendo el método compareTo para la cola de prioridad @Override public int compareTo(Node other) { return this.weight - other.weight; } } // Método para agregar un nodo al grafo public void addNode(int node) { // Agregar el nodo a la lista de adyacencia si aún no está presente adjList.putIfAbsent(node, new ArrayList<>()); } // Método para agregar una arista al grafo public void addEdge(int source, int destination, int weight) { // Agregar arista desde el origen al destino con el peso dado adjList.get(source).add(new Node(destination, weight)); // Para grafos no dirigidos, también agregar arista desde el destino al origen // adjList.get(destination).add(new Node(source, weight)); } // Algoritmo de Dijkstra para encontrar el camino más corto desde el inicio hasta el final public List<Integer> dijkstra(int start, int end) { // Arreglo para almacenar la distancia más corta desde el inicio hasta cada nodo int[] distances = new int[adjList.size()]; Arrays.fill(distances, Integer.MAX_VALUE); // Llenar el arreglo de distancias con el valor máximo distances[start] = 0; // La distancia desde el inicio hasta sí mismo es 0 // Cola de prioridad para los nodos a explorar PriorityQueue<Node> pq = new PriorityQueue<>(); pq.add(new Node(start, 0)); // Agregar el nodo de inicio a la cola boolean[] visited = new boolean[adjList.size()]; // Arreglo visitado para rastrear los nodos visitados // Mientras haya nodos que explorar while (!pq.isEmpty()) { Node current = pq.poll(); // Obtener el nodo con la distancia más pequeña visited[current.node] = true; // Marcar el nodo como visitado // Explorar todos los vecinos del nodo actual for (Node neighbor : adjList.get(current.node)) { if (!visited[neighbor.node]) { // Si el vecino no está visitado int newDist = distances[current.node] + neighbor.weight; // Calcular la nueva distancia if (newDist < distances[neighbor.node]) { // Si la nueva distancia es más corta distances[neighbor.node] = newDist; // Actualizar la distancia pq.add(new Node(neighbor.node, distances[neighbor.node])); // Agregar el vecino a la cola } } } } // Reconstruir el camino más corto desde el final hasta el inicio List<Integer> path = new ArrayList<>(); for (int at = end; at != start; at = distances[at]) { path.add(at); } path.add(start); Collections.reverse(path); // Invertir el camino de inicio a final return path; // Devolver el camino más corto } // Método principal public static void main(String[] args) { Graph graph = new Graph(); // Crear un nuevo grafo // Agregar nodos y aristas al grafo graph.addNode(0); graph.addNode(1); graph.addNode(2); graph.addNode(3); graph.addEdge(0, 1, 1); // Arista desde el nodo 0 al 1 con peso 1 graph.addEdge(1, 2, 3); // Arista desde el nodo 1 al 2 con peso 3 graph.addEdge(2, 3, 1); // Arista desde el nodo 2 al 3 con peso 1 graph.addEdge(0, 3, 10); // Arista desde el nodo 0 al 3 con peso 10 // Ejecutar el algoritmo de Dijkstra para encontrar el camino más corto List<Integer> shortestPath = graph.dijkstra(0, 3); // Encontrar el camino más corto desde el Nodo 0 al Nodo 3 System.out.println("Camino más corto desde el Nodo 0 al Nodo 3: " + shortestPath); // Salida esperada: [0, 1, 2, 3] }}
En este código, creamos un gráfico simple con cuatro nodos (0, 1, 2, 3) y aristas entre ellos con pesos específicos. Luego se utiliza el algoritmo de Dijkstra para encontrar el camino más corto desde el nodo 0 hasta el nodo 3. El método dijkstra calcula las distancias más cortas desde el nodo de inicio hasta todos los demás nodos, y luego reconstruimos el camino más corto hasta el nodo final.
El resultado esperado para el gráfico dado será el camino más corto desde el nodo 0 hasta el nodo 3, considerando los pesos de las aristas.
Puntos clave
Las estructuras de datos de gráficos son esenciales para representar redes complejas y relaciones en diversas disciplinas. Ahora comprendes su papel crucial y su capacidad de adaptación, y has aprendido sobre sus aplicaciones prácticas y su importancia en la resolución de problemas del mundo real.
Nodos cúbicos resplandecientes e interconectados dispuestos en una formación circular con rayos de luz, que representan la estructura de una tabla hash con sus funciones de hash conectando elementos de datos. - Fuente: lunartech.ai
10. Estructura de datos de tabla hash
En el intrincado panorama de las estructuras de datos, la tabla hash destaca por su eficiencia y practicidad. Las tablas hash son una herramienta vital en la informática moderna, esencial para cualquiera que busque optimizar la recuperación y gestión de datos.
¿Qué hace una tabla hash?
Las tablas hash son más que un concepto inteligente, son una potencia en la gestión de datos. En su núcleo, almacenan pares clave-valor, lo que permite una recuperación de datos ultrarrápida.
¿Por qué es esto un cambio de juego? Las tablas hash son fundamentales para agilizar las consultas de bases de datos y son el fundamento de los arreglos asociativos. Si tu objetivo es el acceso rápido a datos y un almacenamiento optimizado, las tablas hash serán una herramienta clave en tu arsenal.
¿Cómo funcionan las tablas hash?
Las tablas hash son fundamentales para administrar datos rápidamente. Un estudio en el International Journal of Computer Science and Information Technologies destaca que las tablas hash pueden mejorar la velocidad de recuperación de datos hasta en un 50% en comparación con los métodos tradicionales. Esta eficiencia es crucial en un mundo donde el volumen de datos está creciendo exponencialmente.
La Dra. Jane Smith, una científica de la computación, enfatiza: "En nuestra era impulsada por datos, comprender y utilizar las tablas hash no es opcional, es imperativo para la eficiencia".
Operaciones clave de la tabla hash
El dominio de las operaciones de tabla hash es clave para aprovechar su poder. Estas incluyen:
Agregar elementos: Insertar nuevos datos en una tabla hash es similar a colocar un nuevo libro en un estante. La función hash procesa la clave, identificando el lugar perfecto para el valor en el arreglo. Esto es crucial para tareas como almacenamiento en caché de datos o almacenamiento de perfiles de usuario.
Eliminar elementos: Para que una tabla hash funcione sin problemas, es esencial eliminar elementos. Este proceso, que implica borrar un par clave-valor, es fundamental en escenarios como la actualización de entradas de caché o la gestión de conjuntos de datos en evolución.
Encontrar elementos: Buscar elementos en una tabla hash es tan sencillo como localizar un libro en una biblioteca. La función hash permite recuperar el valor asociado con una clave específica fácilmente, lo cual es una característica esencial en búsquedas de bases de datos y recuperación de datos.
Iterar sobre elementos: Moverse elemento por elemento en una tabla hash es como hojear una lista de títulos de libros. Este proceso es vital para tareas que requieren examinar o procesar todos los datos almacenados.
Consideraciones de rendimiento de las tablas hash
El rendimiento es donde las tablas hash realmente brillan:
Complejidades de tiempo y espacio: Las operaciones de inserción, eliminación y búsqueda generalmente tienen una complejidad de tiempo de O(1), lo que demuestra la eficiencia de las tablas hash. Pero en escenarios con colisiones frecuentes, esto puede extenderse a O(n). Las operaciones de recorrido tienen una complejidad de tiempo de O(n), según el número de elementos.
Complejidad de espacio y uso de memoria: Las tablas hash en general tienen una complejidad de espacio de O(n), reflejando la memoria utilizada para el almacenamiento de datos y la estructura de arreglo.
Ejemplo de código de tabla hash
import java.util.Hashtable;public class HashTableExample { public static void main(String[] args) { // Crear una tabla hash Hashtable<Integer, String> hashTable = new Hashtable<>(); // Agregar elementos a la tabla hash hashTable.put(1, "Alice"); hashTable.put(2, "Bob"); hashTable.put(3, "Charlie"); // La tabla hash ahora contiene: {1=Alice, 2=Bob, 3=Charlie} System.out.println("Elementos agregados: " + hashTable); // Resultado: Elementos agregados: {3=Charlie, 2=Bob, 1=Alice} // Eliminar un elemento de la tabla hash hashTable.remove(2); // La tabla hash después de la eliminación: { 1=Alice, 3=Charlie} System.out.println("Después de eliminar la clave 2: " + hashTable); // Resultado: Después de eliminar la clave 2: {3=Charlie, 1=Alice} // Encontrar un elemento en la tabla hash String elementoEncontrado = hashTable.get(1); // Elemento encontrado con clave 1: Alice System.out.println("Elemento encontrado con clave 1: " + elementoEncontrado); // Resultado: Elemento encontrado con clave 1: Alice // Iterar sobre los elementos en la tabla hash System.out.println("Iterando sobre la tabla hash:"); for (Integer clave : hashTable.keySet()) { String valor = hashTable.get(clave); System.out.println("Clave: " + clave + ", Valor: " + valor); // Resultado para cada elemento en la tabla hash } }}
Ventajas y Limitaciones de las Tablas Hash
Las tablas hash ofrecen un acceso rápido a los datos y una recuperación eficiente basada en claves, lo que las hace ideales para escenarios donde la velocidad es crucial.
Pero podrían no ser la mejor opción cuando el orden de los elementos es esencial, o en situaciones donde el uso de memoria es una preocupación principal.
Puntos Clave
Las tablas hash son más que una estructura de datos: son una herramienta estratégica en la gestión de datos. Su capacidad para mejorar la eficiencia de la recuperación y procesamiento de datos las hace indispensables en la computación moderna.
A medida que navegamos en un mundo cada vez más centrado en los datos, la comprensión y aplicación de las tablas hash no solo es beneficiosa. Es esencial para aquellos que deseen mantenerse adelante en el campo de la tecnología.
Una explosión de rayos de luz dinámica que emana de un núcleo central rodeado de iconos simbólicos de datos, representando el potencial desatado de las estructuras de datos en la programación. - Fuente: lunartech.ai
11. Cómo Desatar el Poder de las Estructuras de Datos en la Programación
Las estructuras de datos son la base de la programación, transformando un buen código en un código excepcional. Más que meras herramientas, son el fundamento que moldea cómo se administra y utiliza los datos.
En la programación, dominar las estructuras de datos es como manejar un superpoder estratégico, elevando la velocidad, eficiencia e inteligencia de tu software. A medida que exploramos las estructuras de datos populares, recuerda: esto se trata de potenciar tu código para que sobresalga.
Potencia la Eficiencia de Tu Código:
Las estructuras de datos se tratan de hacer más con menos. Son la clave para potenciar el rendimiento de tu código.
Imagínalo: usar una tabla hash puede convertir una operación de búsqueda lenta en una recuperación ultrarrápida. O considera una lista enlazada, que puede facilitar la adición o eliminación de elementos. Es como tener un tren de alta velocidad en lugar de un carro de caballos para tus datos.
Resuelve Problemas Como un Profesional:
Las estructuras de datos son tu navaja suiza para enfrentar desafíos complejos. Te brindan una manera de descomponer y organizar los datos, haciendo que incluso los problemas más difíciles sean manejables.
¿Necesitas mapear una jerarquía? Los árboles están ahí para ayudarte. ¿Estás trabajando con datos en red? Los grafos son tu mejor opción. Se trata de tener la herramienta adecuada para el trabajo.
Flexibilidad al Alcance de Tus Dedos:
La belleza de las estructuras de datos radica en su variedad. Cada una viene con su propio conjunto de habilidades, listas para ser utilizadas según las necesidades de tu programa.
Esto significa que puedes adaptar tu enfoque para ajustarse a la tarea en cuestión, haciendo que tu software sea más adaptable y robusto. Es como ser un chef con una amplia variedad de especias: las posibilidades son infinitas.
Optimiza la Memoria:
En el mundo de la programación, la memoria es oro, y las estructuras de datos te ayudan a gastarla sabiamente. Son los arquitectos de la memoria, construyéndola y gestionándola de manera eficiente.
Por ejemplo, los arreglos dinámicos son como unidades de almacenamiento expansibles, que crecen y se reducen según sea necesario. Al dominar las estructuras de datos, te conviertes en un administrador de memoria, asegurándote de que no se desaproveche ni un byte.
Crece Sin Esfuerzo:
A medida que tu software crece, también aumentan sus demandas. Aquí es donde las estructuras de datos entran en juego. Están diseñadas para el crecimiento.
Los árboles de búsqueda binaria equilibrados, por ejemplo, son excelentes para administrar conjuntos de datos grandes, manteniendo búsquedas y clasificaciones rápidas sin importar el tamaño. Elegir la estructura de datos correcta significa que tu código puede manejar el crecimiento sin problemas.
Puntos Clave
Las estructuras de datos son los pilares que respaldan la programación excelente. Aportan eficiencia, habilidad para resolver problemas, adaptabilidad, optimización de memoria y escalabilidad a tu conjunto de herramientas de programación.
Comprender y utilizar estas herramientas no solo es una habilidad, sino un cambio de juego en el mundo de la programación. Aprovecha al máximo estas potentes herramientas y observa cómo tu código se transforma de bueno a excepcional.
Radiantes y organizados caminos que se extienden desde un punto central hacia diferentes símbolos de datos, ilustrando el proceso de toma de decisiones para seleccionar la estructura de datos apropiada para una aplicación. - Fuente: lunartech.ai
12. Cómo elegir la estructura de datos adecuada para tu aplicación
Seleccionar la estructura de datos adecuada es una decisión fundamental en el desarrollo de software, ya que influye directamente en la eficiencia, rendimiento y escalabilidad de tu aplicación.
No se trata solo de elegir una herramienta, sino de alinear tu código con las necesidades de tu proyecto para obtener una funcionalidad óptima. Veamos los factores esenciales a considerar para tomar esta decisión crítica.
Aclarar las necesidades de tu aplicación
El primer paso es comprender los requisitos específicos de tu aplicación. ¿Con qué tipo de datos estás trabajando? ¿Qué operaciones llevarás a cabo? ¿Existen alguna restricción?
Por ejemplo, si la búsqueda rápida es una prioridad, ciertas estructuras como las tablas hash pueden ser ideales. Pero si te preocupa más la inserción o eliminación eficiente de datos, podría ser mejor usar una lista enlazada. Se trata de adaptar la estructura de datos a tus necesidades únicas.
Analizar complejidad temporal y espacial
Cada estructura de datos tiene su propio conjunto de complejidades. Un árbol de búsqueda binaria puede ofrecer tiempos de búsqueda rápidos, pero a costa de más memoria. Por otro lado, una simple matriz puede ser eficiente en memoria, pero más lenta en operaciones de búsqueda. Analiza estos factores en función de las metas de rendimiento de tu aplicación para encontrar el equilibrio adecuado.
Predecir el tamaño y crecimiento de los datos
¿Cuántos datos manejará tu aplicación y cómo podrían cambiar con el tiempo? Para conjuntos de datos pequeños o estáticos, estructuras simples podrían ser suficientes. Pero si esperas un crecimiento o lidias con grandes volúmenes de datos, necesitarás algo más robusto, como un árbol balanceado o una tabla hash.
Anticipar la trayectoria de tus datos es clave para elegir una estructura que no solo funcione hoy, sino que continúe funcionando a medida que tu aplicación crezca.
Evaluar los patrones de acceso a los datos
¿Cómo accederás a tus datos? ¿De manera secuencial o aleatoria? La respuesta a esta pregunta puede influir en gran medida en tu elección. Por ejemplo, los arreglos son excelentes para acceso secuencial, mientras que las tablas hash destacan en escenarios de acceso aleatorio.
Comprender tus patrones de acceso te ayuda a elegir una estructura que optimice tus operaciones más frecuentes.
Considerar las limitaciones de memoria
Finalmente, ten en cuenta el entorno de memoria de tu aplicación. Algunas estructuras de datos consumen más memoria que otras. Si tienes limitaciones estrictas de memoria, esto podría ser un factor decisivo. Opta por estructuras que ofrezcan la funcionalidad que necesitas sin sobrecargar la memoria de tu sistema.
Puntos clave
En resumen, elegir la estructura de datos adecuada implica comprender los requisitos únicos de tu aplicación y alinearse con las fortalezas y limitaciones de diferentes estructuras. Es una decisión que requiere previsión, análisis y una comprensión clara de las metas de tu proyecto.
Con estas consideraciones en mente, estarás bien preparado para tomar una decisión que mejore el rendimiento y la escalabilidad de tu aplicación.
Una figura en una estación de trabajo con árboles y estructuras digitales ramificándose desde un centro luminoso, simbolizando la implementación estratégica de estructuras de datos en la programación. Fuente: lunartech.ai
13. Cómo implementar eficientemente estructuras de datos
En el mundo del desarrollo de software, elegir y utilizar estructuras de datos de manera eficiente puede marcar la diferencia en el rendimiento de tu sistema. Aquí tienes una guía concisa para asegurarte de que tus estructuras de datos no solo estén implementadas, sino optimizadas para un rendimiento máximo.
Seleccionar la herramienta adecuada para el trabajo
Un chef elige un cuchillo o una licuadora dependiendo de lo que esté preparando. De manera similar, usa una lista enlazada cuando necesites insertar o eliminar elementos con frecuencia en ambos extremos, como gestionar una lista de tareas donde las tareas pueden cambiar de prioridad.
Un arreglo es excelente para una lista estática de puntuaciones altas en un juego, pero una tabla hash destaca al desarrollar una aplicación de agenda de contactos donde es crucial la recuperación rápida de los detalles de un contacto.
Comprender el costo de tus decisiones
Ten en cuenta los intercambios de espacio y tiempo. Un grafo puede ser necesario para representar una red social con conexiones complejas, pero un árbol es más eficiente para organizar la estructura jerárquica de una empresa, y una pila podría ser la mejor opción para la funcionalidad de deshacer en un editor de texto.
Codifica con Claridad y Estándares
Es como escribir una receta que otros puedan seguir fácilmente. Utiliza nombres de variables descriptivos como 'maxHeight' en lugar de 'mh' y comenta el propósito detrás de un algoritmo complejo, lo que facilitará futuras actualizaciones o depuraciones por parte de tus colegas, o incluso de ti mismo.
Prepárate para lo Inesperado
El manejo de errores es como tener un seguro; puede parecer innecesario hasta que lo necesitas. Configura mensajes de error claros y soluciones alternativas para cuando no se pueda encontrar un archivo o falle una solicitud de red, al igual que una aplicación de GPS ofrece rutas alternativas cuando el camino deseado no está disponible.
Administra la Memoria Minuciosamente
Es como mantener la cocina ordenada mientras cocinas. Evita las fugas de memoria liberando la memoria en lenguajes como C, de manera similar a limpiar mientras avanzas para no terminar con un espacio de trabajo desordenado o, peor aún, un programa que se estrella debido al uso de toda la memoria disponible.
Prueba, y luego prueba aún más
Es como corregir un artículo múltiples veces antes de publicarlo. Las pruebas exhaustivas deben incluir casos límite, como verificar cómo una estructura de datos de pila maneja la inserción y extracción cuando está vacía o llena, para asegurarte de que cuando tu aplicación esté en funcionamiento, proporcione una experiencia fluida.
Nunca Dejes de Optimizar
Continuamente mejora tu código como un editor puliría un manuscrito. El perfilado podría revelar que cambiar una lista por un conjunto en una función que verifica la pertenencia mejora significativamente la velocidad, al igual que utilizar una ruta más eficiente reduce el tiempo de viaje. Mantente al día con los últimos algoritmos y refactoriza el código cuando sea necesario para mantener una ventaja.
Puntos clave a tener en cuenta
El dominio de las estructuras de datos consiste en tomar decisiones informadas, escribir código claro y fácil de mantener, prepararse para lo inesperado, administrar los recursos sabiamente y comprometerse con pruebas y optimizaciones continuas. Estas prácticas transforman el buen software en excelente software, asegurando que tus estructuras de datos no solo se implementen, sino que también funcionen de manera óptima.
Autopista futurista con flujos de luz viajando a alta velocidad, rodeada de estructuras geométricas complejas e iluminadas, que encarnan el concepto de optimizar el rendimiento de las estructuras de datos a través de la comprensión de las complejidades del tiempo. Fuente: lunartech.ai
14. Cómo optimizar el rendimiento: Comprender las complejidades del tiempo en estructuras de datos
En el mundo de la ciencia de la computación, las estructuras de datos son más que simples mecanismos de almacenamiento: son los arquitectos de la eficiencia. Saber cómo navegar por sus operaciones y complejidades temporales es más que útil; representa un cambio de juego para optimizar tus algoritmos y potenciar el rendimiento de tu software.
Vamos a desglosar las operaciones más comunes y sus complejidades temporales.
Inserción: (O(1) a O(n))
La inserción es como agregar un nuevo jugador a tu equipo. Rápido y sencillo en algunas estructuras, más lento en otras.
Por ejemplo, agregar un elemento al principio de una lista enlazada es una operación rápida de O(1). Pero, si estás insertando al final, podría tomar tiempo O(n), ya que puede que debas recorrer toda la lista.
Eliminación: (O(1) a O(n))
Imagina la eliminación como quitar una pieza de un rompecabezas. En algunos casos, como eliminar de un arreglo o una lista enlazada en un índice específico, es una acción rápida de O(1). Pero en estructuras como árboles binarios de búsqueda o tablas hash, es posible que necesites recorrer todo el árbol o tabla con una complejidad O(n) para encontrar y eliminar tu objetivo.
Búsqueda: (O(1) a O(n))
La búsqueda es como tratar de encontrar una aguja en un pajar. En un arreglo o tabla hash, a menudo es un proceso muy rápido de O(1). Pero en un árbol binario de búsqueda o una lista enlazada, es posible que debas revisar cada elemento, lo que eleva la complejidad de tiempo a O(n).
Acceso: (O(1) a O(n))
Acceder a los datos es como tomar un libro de un estante. En arreglos o listas enlazadas, agarrar un elemento en un índice específico es una tarea rápida O(1). Pero en estructuras más complejas como árboles binarios o tablas hash, es posible que necesites navegar a través de varios nodos, lo que conlleva una complejidad de tiempo O(n).
Ordenamiento: (O(n log n) a O(n²))
Ordenar se trata de poner tus patitos en fila. La eficiencia varía ampliamente según el algoritmo que elijas.
Clásicos como Quicksort, Mergesort y Heapsort generalmente operan en el rango de O(n log n). Pero ten cuidado con los métodos menos eficientes que pueden llegar a tener una complejidad de O(n²).
Principales puntos a tener en cuenta
Entender estas complejidades de tiempo es clave al elegir qué estructura de datos usar. Se trata de elegir la correcta para el trabajo, asegurando que tu software no solo funcione, sino que funcione eficientemente.
Ya sea que estés construyendo una nueva aplicación o optimizando una existente, estos conocimientos son tu guía hacia una solución de alto rendimiento.
Un conjunto de vibrantes bloques de ciudad iluminados con neón, cada uno representando diferentes estructuras de datos, con vías de conexión que simbolizan aplicaciones e interacciones del mundo real. - Fuente: lunartech.ai
15. Ejemplos del Mundo Real de Estructuras de Datos en Acción
Las estructuras de datos no son solo conceptos teóricos; son los motorcitos silenciosos detrás de muchas de las tecnologías que usamos a diario. Su papel en la organización, almacenamiento y gestión de datos es fundamental para hacer nuestras experiencias digitales fluidas y eficientes.
Exploraremos cómo estos héroes no reconocidos del mundo tecnológico tienen un impacto real en diversas aplicaciones.
Función Deshacer en Editores de Texto:
¿Alguna vez has presionado 'deshacer' en un editor de texto y te has maravillado de cómo recupera tu última acción? Eso es una estructura de datos de pila en acción. Cada acción que realizas se "empuja" en la pila. Presiona 'deshacer' y la pila "expulsa" la acción más reciente, revirtiendo tu documento a su estado anterior. Simple, pero ingenioso.
Plataformas de Redes Sociales:
Plataformas como Facebook y Twitter no se tratan solo de conectar personas, sino de administrar enormes redes de datos. Aquí es donde entran en juego las estructuras de datos de grafo. Mapean la compleja red de conexiones e interacciones entre usuarios, haciendo posible y muy eficiente características como sugerencias de amigos y seguimiento de relaciones.
Sistemas de Navegación GPS:
¿Alguna vez te has preguntado cómo tu GPS calcula la ruta más rápida? Utiliza grafos y árboles para representar las redes de carreteras, con algoritmos que recorren estos datos para encontrar el camino más corto. Esto no se trata solo de llevarte del punto A al punto B, sino de hacerlo de la manera más eficiente posible.
Motores de Recomendación de Comercio Electrónico:
Cuando una tienda online parece leer tu mente con sugerencias de productos perfectas, agradece a las estructuras de datos como tablas hash y árboles. Analizan tus hábitos de compra, preferencias e historial, utilizando estos datos para adaptar recomendaciones que a menudo parecen sorprendentemente precisas.
Organización del Sistema de Archivos:
La capacidad de tu computadora para almacenar y recuperar archivos rápidamente se debe a las estructuras de datos. Los árboles ayudan a organizar directorios, facilitando la navegación de archivos. Mientras tanto, métodos como listas enlazadas y mapas de bits llevan un seguimiento del espacio de almacenamiento, asegurando una gestión de archivos eficiente.
Indexación de Motores de Búsqueda:
La velocidad a la que los motores de búsqueda como Google entregan resultados relevantes se debe a las estructuras de datos. Los índices invertidos vinculan palabras clave con páginas web que las contienen, mientras que los árboles y las tablas hash almacenan esta información para su recuperación rápida. Esto no es solo buscar, sino encontrar agujas en un pajar digital a una velocidad increíble.
Una intrincada red de nodos y herramientas digitales iluminados e interconectados, que representa los recursos y metodologías esenciales para dominar las estructuras de datos. - Fuente: lunartech.ai
16. Kit Esencial para Aprender Estructuras de Datos
Navegar por el mundo de las estructuras de datos puede ser desalentador, pero los recursos y herramientas adecuados pueden convertir este viaje en una experiencia enriquecedora.
Ya sea que estés comenzando o buscando profundizar tu experiencia, los siguientes recursos seleccionados son tus aliados para dominar el arte de las estructuras de datos.
CodesCode: Una comunidad de código abierto donde puedes aprender a programar de forma gratuita. Ofrece desafíos y proyectos interactivos de codificación, además de artículos y videos para reforzar tus conocimientos en algoritmos y estructuras de datos. ¡Bingo!
"Introducción a los algoritmos" por Cormen, Leiserson, Rivest y Stein: Este libro seminal es un tesoro de sabiduría algorítmica, ofreciendo una inmersión profunda en los principios y técnicas de las estructuras de datos.
"Estructuras de Datos y Algoritmos: Referencia Anotada con Ejemplos" por Granville Barnett y Luca Del Tongo: Una guía práctica que desmitifica las estructuras de datos con explicaciones claras y ejemplos del mundo real, perfecta para autodidactas.
Coursera: Un centro de cursos en línea de primer nivel de universidades reconocidas, que ofrece caminos de aprendizaje estructurados y tareas prácticas para consolidar tu comprensión de las estructuras de datos y algoritmos.
VisuAlgo: Llevando las estructuras de datos a la vida con visualizaciones animadas, esta herramienta simplifica conceptos complejos, haciéndolos más accesibles y comprensibles.
Visualizaciones de Estructuras de Datos: Una plataforma que ofrece representaciones visuales interactivas, que te permiten explorar y comprender los mecanismos de las estructuras de datos comunes.
LeetCode: Un amplio repositorio de desafíos de programación, incluyendo problemas específicos de estructuras de datos, para perfeccionar tus habilidades de programación en un contexto del mundo real.
HackerRank: Con su extenso conjunto de desafíos, esta plataforma es una excelente arena para aplicar y mejorar tus habilidades de implementación de estructuras de datos.
Stack Overflow: Accede a la sabiduría colectiva de una vasta comunidad de programadores, un recurso valioso para solucionar problemas y obtener información de desarrolladores experimentados.
Reddit: Descubre comunidades de programación donde las discusiones sobre estructuras de datos florecen, ofreciendo oportunidades de grupos de estudio y recomendaciones de recursos.
Estos recursos son más que simples ayudas de aprendizaje: son puertas de entrada a una comprensión más profunda y a la aplicación práctica de las estructuras de datos. Recuerda, el mejor enfoque para el aprendizaje es aquel que se alinea con tu estilo personal y ritmo. Utiliza estas herramientas para elevar tu conocimiento de estructuras de datos a nuevas alturas.
Un sendero luminoso que conduce hacia un horizonte brillante, rodeado de íconos de datos y palabras clave estratégicas, simbolizando el viaje hacia una conclusión y pasos accionables en el mundo de las estructuras de datos. - Fuente: lunartech.ai
17. Conclusión y Pasos Accionables
Armado con un conocimiento integral de las estructuras de datos, ahora estás preparado para aprovechar todo su potencial. Aquí tienes los puntos clave y los pasos accionables para guiar tu continuo viaje:
Practica y Experimenta
Aplica tus conocimientos implementando diferentes estructuras de datos en diferentes lenguajes de programación. Este enfoque práctico solidifica tu comprensión y mejora tus habilidades para resolver problemas.
Explora Estructuras Avanzadas:
Aventúrate más allá de lo básico hacia estructuras de datos más complejas como árboles, grafos y tablas hash. Comprender sus matices mejorará significativamente tu capacidad para enfrentar desafíos de programación sofisticados.
Sumérgete en los Algoritmos:
Combina tus conocimientos de estructuras de datos con un estudio de algoritmos. Familiarízate con técnicas de ordenamiento, búsqueda y recorrido de grafos para optimizar tu código y resolver eficientemente problemas computacionales complejos.
Mantente Informado y Comprometido:
Mantente al tanto del panorama de la ingeniería de software en constante evolución. Sigue blogs de la industria, asiste a conferencias tecnológicas y participa en comunidades de programación para mantenerte a la vanguardia.
Colabora y Comparte:
Únete a tus colegas en comunidades de desarrollo. Trabajar en proyectos de programación juntos ofrece nuevas perspectivas y afila tus habilidades. Contribuir a proyectos de código abierto también es una excelente manera de retribuir y consolidar tu experiencia.
Muestra tus Habilidades:
Construye un portafolio que resalte tu competencia en el uso de estructuras de datos para resolver problemas del mundo real. Esta exhibición tangible de tus habilidades es invaluable para impresionar a posibles empleadores o clientes.
Aprovecha el viaje para dominar las estructuras de datos. Es un camino que conduce a codificación optimizada, resolución eficiente de problemas y una presencia destacada en el mundo de la ingeniería de software. Sigue aprendiendo, experimentando y compartiendo tus conocimientos, y observa cómo se abren puertas hacia nuevas oportunidades y avances en tu carrera.
Un libro abierto que irradia un espectro de luz y datos, con gráficos vibrantes, formas geométricas y patrones en espiral que simbolizan la convergencia del conocimiento y la culminación de ideas sobre estructuras de datos y sus aplicaciones en tecnología. - Fuente: lunartech.ai
18. Conclusión
En resumen, aprender a utilizar estructuras de datos es fundamental para cualquier aspirante a ingeniero de software. Al entender estas estructuras, puedes mejorar el rendimiento de tu código, garantizar la escalabilidad y construir aplicaciones robustas.
Desde matrices y listas enlazadas fundamentales hasta árboles y grafos complejos, cada estructura ofrece beneficios y aplicaciones únicas.
Continúa explorando adentrándote en los algoritmos y sus implementaciones prácticas. Mantén la curiosidad, practica diligentemente y únete a nuestra comunidad de profesionales comprometidos con la excelencia en ingeniería de software. Ofrecemos una gran cantidad de recursos, cursos y oportunidades de networking para apoyar tu crecimiento y éxito en este campo dinámico.
Recursos
Si estás interesado en dominar las estructuras de datos, echa un vistazo al Bootcamp de Maestría en Estructuras de Datos de LunarTech.AI. Es perfecto para aquellos interesados en IA y aprendizaje automático, enfocándose en el uso efectivo de estructuras de datos en la codificación. Este programa integral cubre estructuras de datos esenciales, algoritmos y programación en Python, e incluye mentoría y apoyo profesional.
Además, para practicar más con las estructuras de datos, explora estos recursos en nuestro sitio web:
Vahe Aslanyan aquí, en el nexo entre la informática, la ciencia de datos y la IA. Visita vaheaslanyan.com para ver un portafolio que es un testimonio de precisión y progreso. Mi experiencia une el desarrollo full-stack y la optimización de productos de IA, impulsados por resolver problemas de nuevas formas.
Vahe Aslanyan - Creando código, dando forma al futurosumérgete en el mundo digital de Vahe Aslanyan, donde cada proyecto ofrece nuevos conocimientos y cada obstáculo allana el camino para el crecimiento.Creando código, dando forma al futuro
Con un historial que incluye el lanzamiento de un bootcamp líder en ciencia de datos y colaboraciones con los mejores especialistas de la industria, mi enfoque sigue siendo elevar la educación tecnológica a estándares universales.
A medida que concluimos el libro de 'Estructuras de Datos', quiero expresar mi gratitud por tu tiempo. Este viaje de destilar años de conocimiento profesional y académico en este manual ha sido un esfuerzo gratificante. Gracias por acompañarme en esta búsqueda y espero con ansias presenciar tu crecimiento en el ámbito tecnológico.


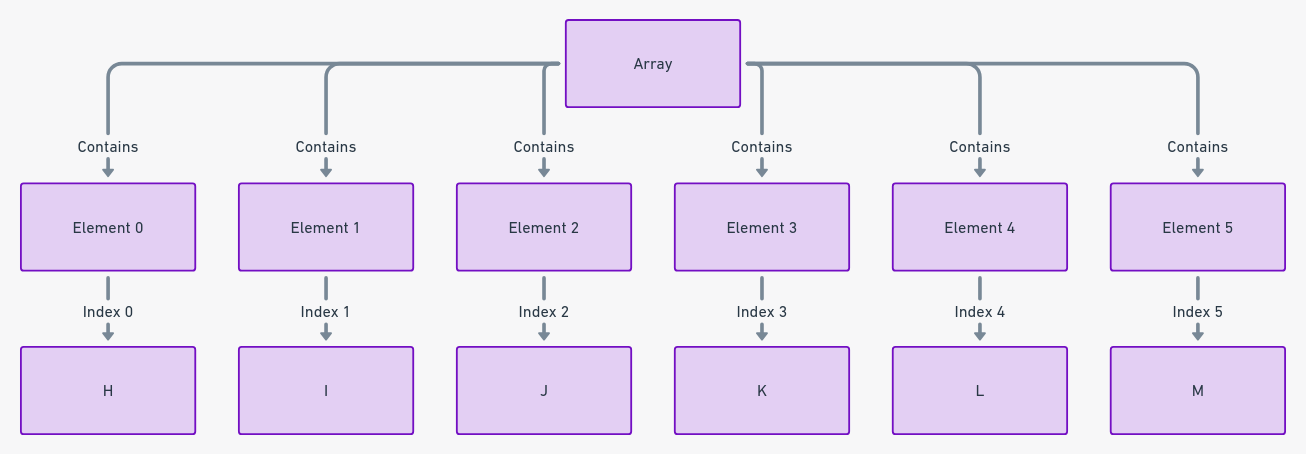
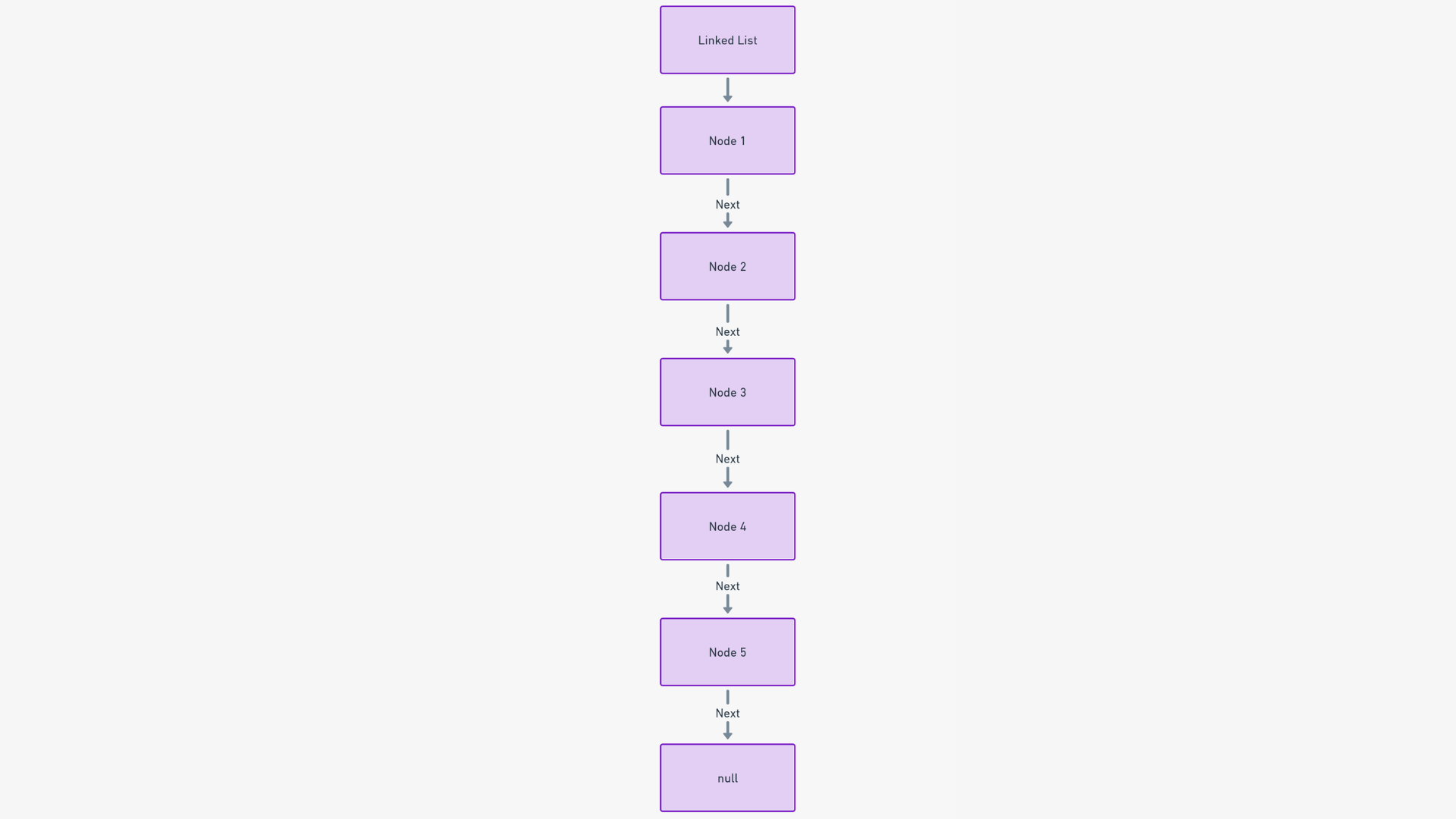
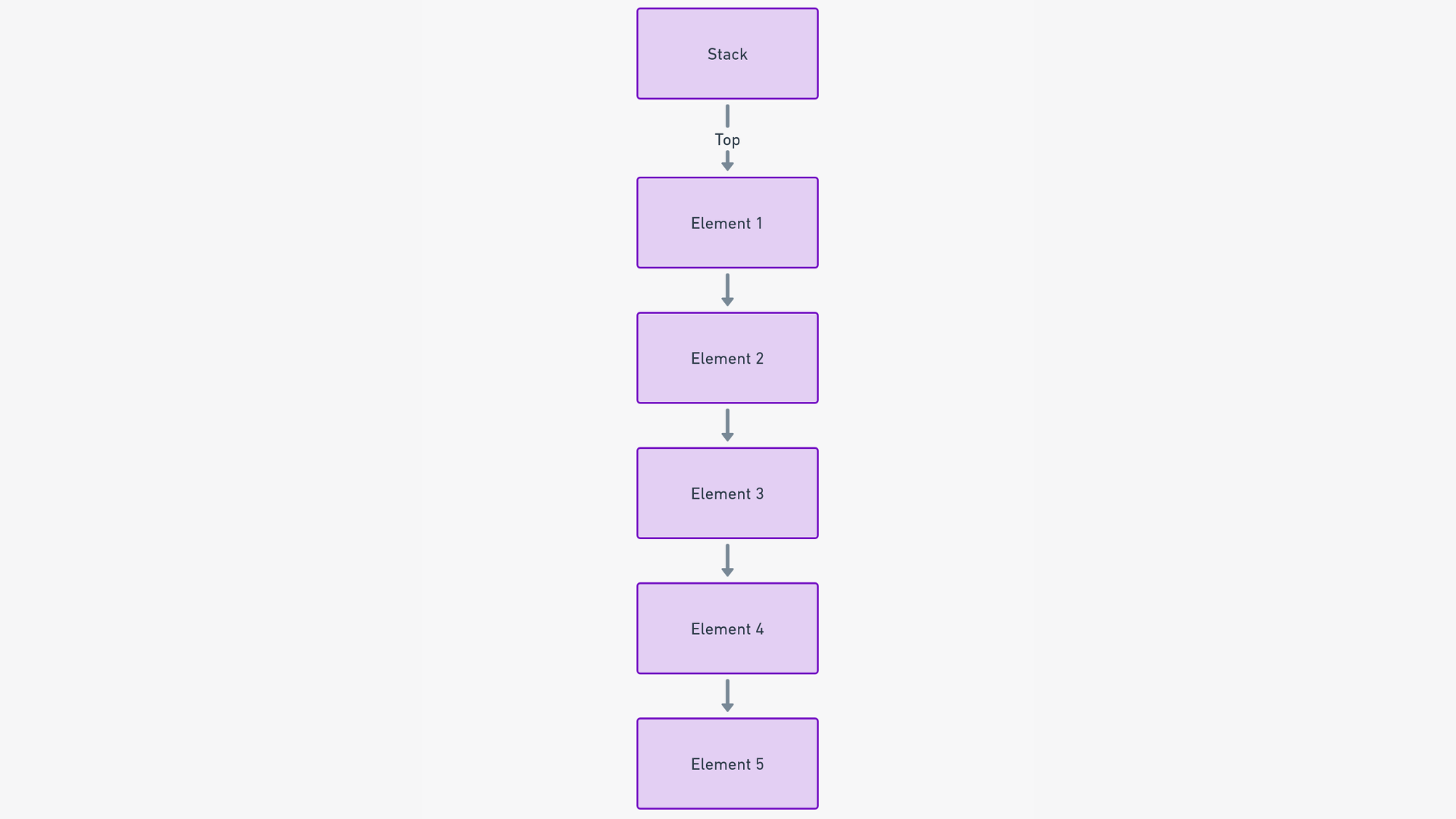
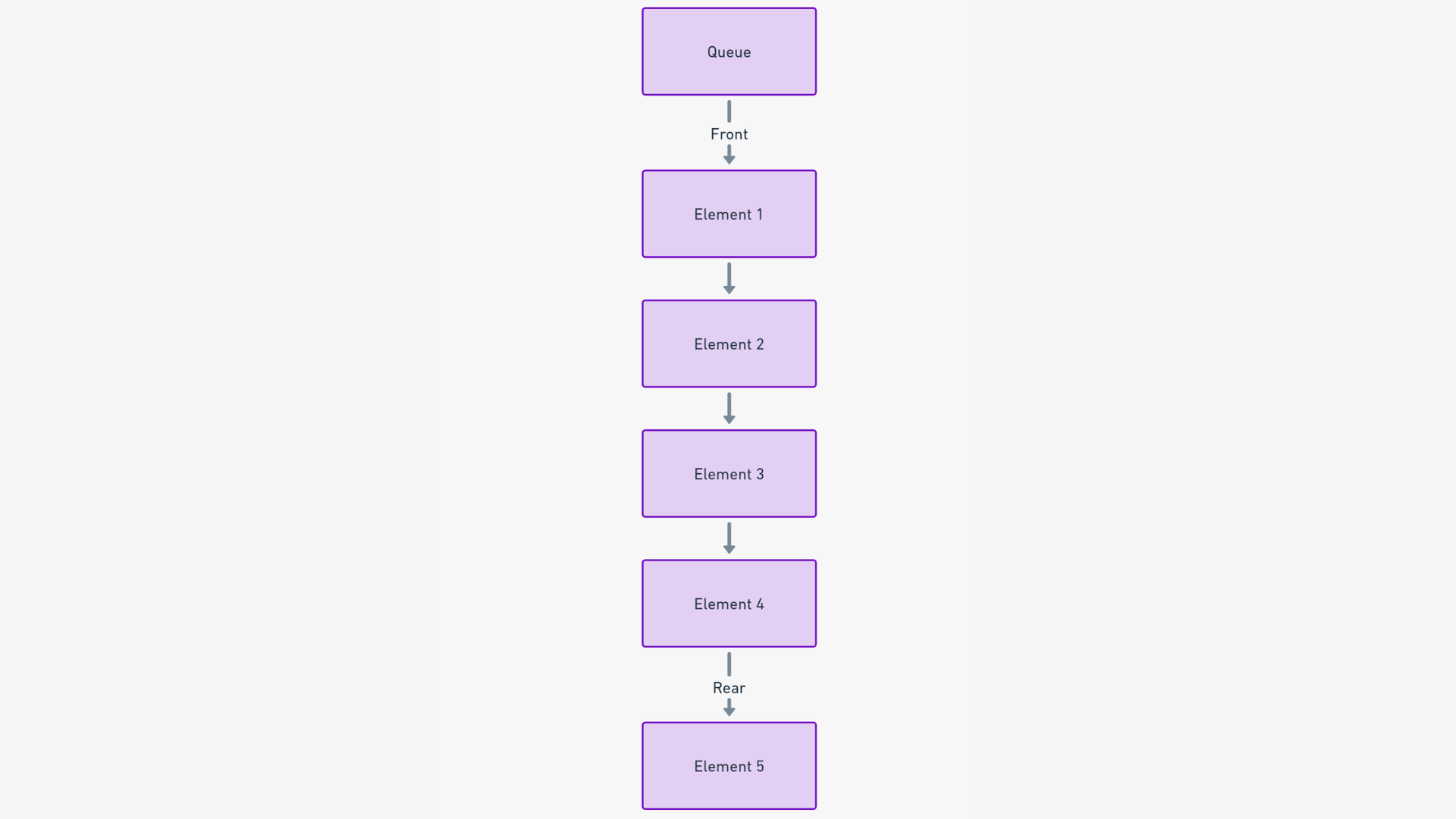
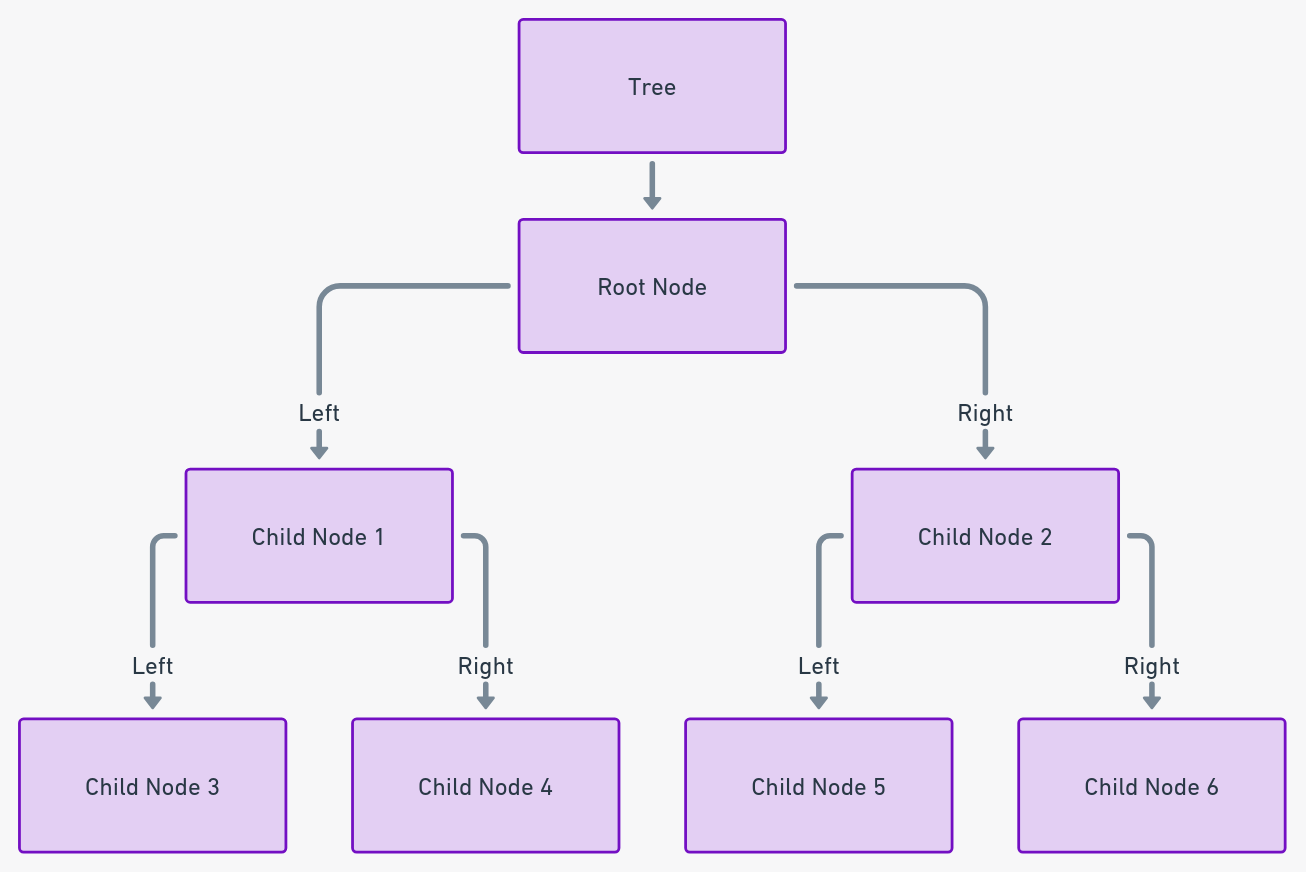
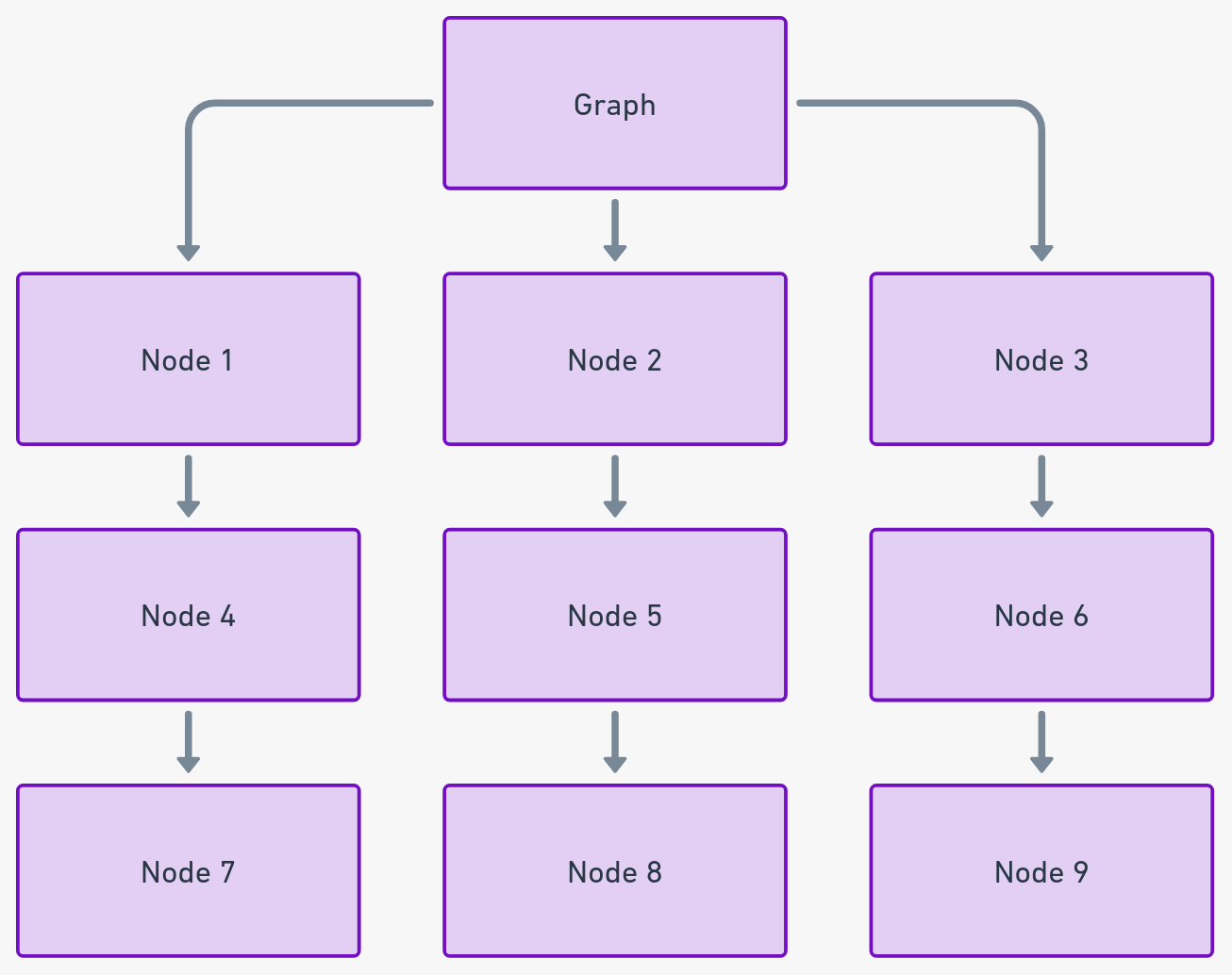
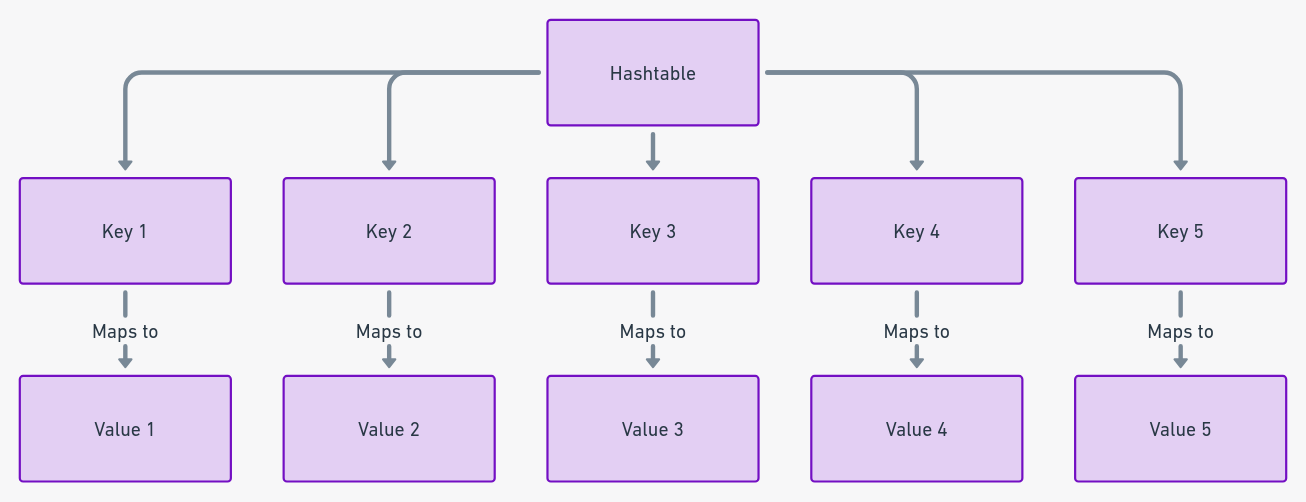
















 Creando código, dando forma al futuro
Creando código, dando forma al futuro









Leave a Reply