Cómo utilizar el Segment Anything Model (SAM) para crear máscaras
¡Hola! ¿Sabías sobre todo ese revuelo acerca del autopilot de Tesla que es tan futurista y sin conductor? ¿Alguna vez te has preguntado cómo hace realmente su magia? Déjame contarte - todo se trata de segmentación de imágenes y detección de objetos. ¿Qué es la Segmentación de Imágenes? La segmentación de imágenes, básicamente, consiste en dividir una imagen en trozos.
¡Hola! Entonces, ¿has escuchado sobre el alboroto del piloto automático de Tesla y cómo es todo futurista y sin conductor? ¿Alguna vez te has preguntado cómo logra hacer su magia? Bueno, déjame decirte que todo se trata de la segmentación de imágenes y la detección de objetos.
¿Qué es la segmentación de imágenes?
La segmentación de imágenes, básicamente dividir una imagen en diferentes partes, ayuda al sistema a reconocer cosas. Identifica dónde se encuentran los humanos, otros autos y obstáculos en la carretera. Esa es la tecnología que garantiza que esos autos autónomos puedan circular de manera segura. Impresionante, ¿verdad? 🚗
En la última década, la visión por computadora ha avanzado enormemente, especialmente en la creación de métodos de segmentación y detección de objetos súper sofisticados.
Estos avances se han utilizado de diversas formas, como para detectar tumores y enfermedades en imágenes médicas, monitorear cultivos en la agricultura e incluso guiar robots en la navegación. La tecnología está expandiéndose y teniendo un impacto significativo en diferentes campos.
El desafío principal radica en obtener y preparar los datos. Construir un conjunto de datos de segmentación de imágenes requiere anotar montones de imágenes para definir las etiquetas, lo cual es una tarea enorme. Esto requiere muchos recursos.
Entonces, el juego cambió cuando apareció el Modelo Segment Anything (SAM). SAM revolucionó este campo al permitir que cualquier persona cree máscaras de segmentación para sus datos sin depender de datos etiquetados.
En este artículo, te guiaré para que comprendas SAM, cómo funciona y cómo puedes utilizarlo para crear máscaras. ¡Así que prepárate con tu taza de café porque nos metemos en el tema! ☕
Prerrequisitos:
Los prerrequisitos para este artículo incluyen un conocimiento básico de programación en Python y una comprensión fundamental de aprendizaje automático.
Además, sería beneficioso estar familiarizado con los conceptos de segmentación de imágenes, visión por computadora y los desafíos de la anotación de datos.
¿Qué es el Modelo Segment Anything?
SAM es un modelo de lenguaje grande que fue desarrollado por el equipo de investigación de Facebook (Meta AI). El modelo fue entrenado en un conjunto de datos masivo de 1.1 mil millones de máscaras de segmentación, el conjunto de datos SA-1B. El modelo puede generalizar bien a datos no vistos porque se entrenó en un conjunto de datos muy diverso y tiene baja varianza.
SAM se puede usar para segmentar cualquier imagen y crear máscaras sin ningún dato etiquetado. Es un avance, ya que antes de SAM no era posible realizar una segmentación completamente automatizada.
¿Qué hace que SAM sea único? Es un modelo de segmentación que se puede guiar mediante instrucciones. Las instrucciones te permiten indicar al modelo qué salida deseas mediante texto y acciones interactivas. Puedes proporcionar instrucciones a SAM de múltiples formas: puntos, cuadros delimitadores, textos e incluso máscaras base.
¿Cómo funciona SAM?
SAM utiliza una arquitectura basada en transformadores, al igual que la mayoría de los modelos de lenguaje grande. Veamos el flujo de datos a través de los diferentes componentes de SAM.
Codificador de Imágenes: Cuando proporcionas una imagen a SAM, esta se envía primero al Codificador de Imágenes. Fiel a su nombre, este componente codifica la imagen en vectores. Estos vectores representan las características de bajo nivel (bordes, contornos) y de alto nivel, como las formas y texturas de los objetos extraídos de la imagen. El codificador utilizado aquí es un Transformador de Visión (ViT), que tiene muchas ventajas sobre las redes neuronales convolucionales tradicionales.
Codificador de Instrucciones: La instrucción que el usuario proporciona se convierte en incrustaciones por el codificador de instrucciones. SAM utiliza incrustaciones posicionales para puntos y cuadros delimitadores, y codificadores de texto para instrucciones de texto.
Decodificador de Máscaras: A continuación, SAM mapea las características de imagen extraídas y las incrustaciones de instrucciones para generar la máscara, que es nuestro resultado. SAM generará 3 máscaras segmentadas para cada instrucción de entrada, lo que brinda opciones a los usuarios.
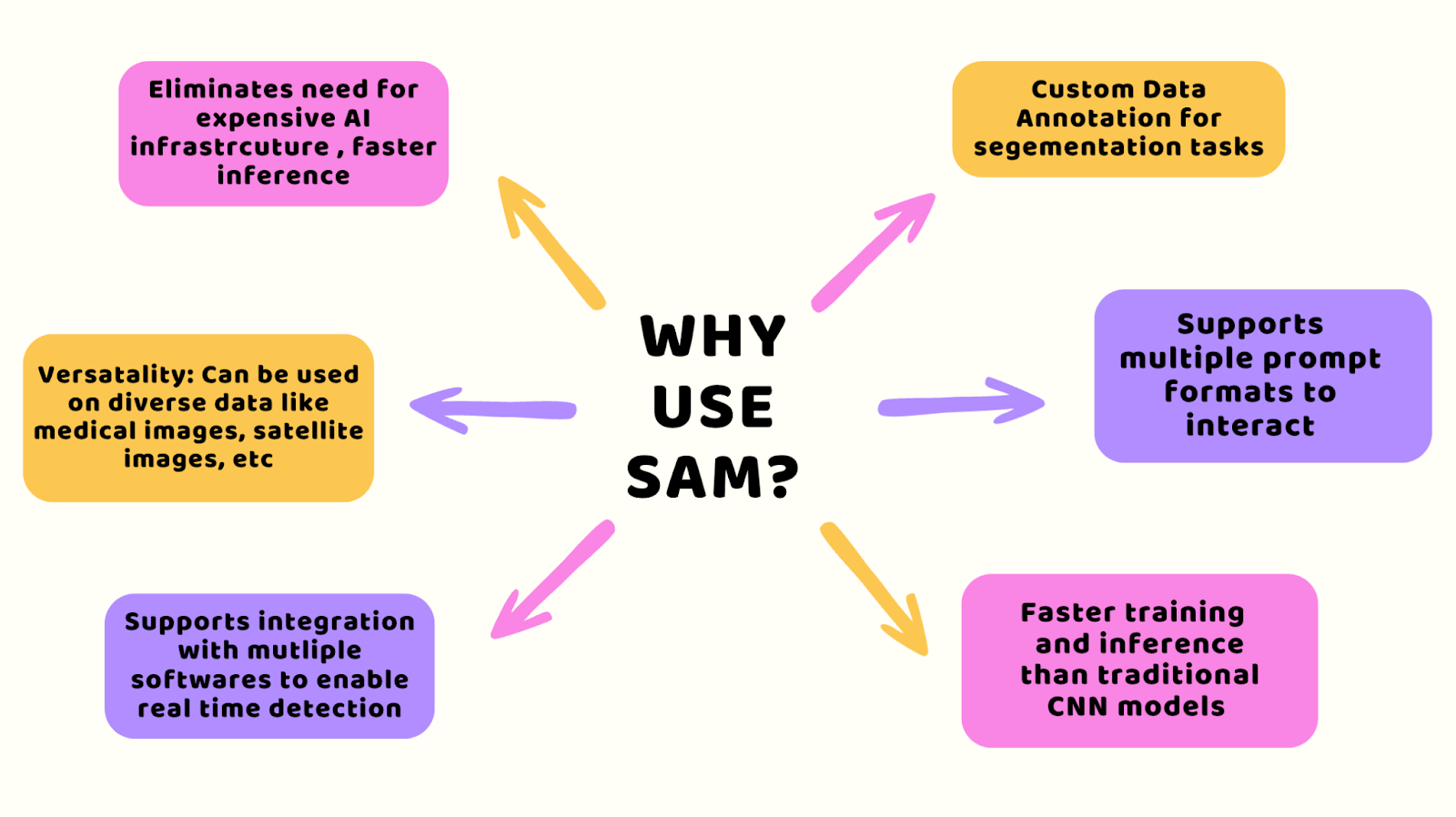
¿Por qué usar SAM?
Con SAM, puedes omitir la costosa configuración que generalmente se necesita para la inteligencia artificial y aún obtener resultados rápidos. Funciona bien con todo tipo de datos, como imágenes médicas o de satélites, y se adapta perfectamente al software que ya utilizas para tareas de detección rápida.
También obtienes herramientas diseñadas para tareas específicas, como la segmentación de imágenes, y es fácil de interactuar con ellas, ya sea que estés entrenándolas o pidiéndoles analizar datos. Además, es más rápido que los sistemas antiguos como las redes neuronales convolucionales, lo que te ahorra tiempo y dinero.
Cómo instalar y configurar SAM
Ahora que sabes cómo funciona SAM, déjame mostrarte cómo instalar y configurarlo. El primer paso es instalar el paquete en tu bloc de notas Jupyter o Google Colab con el siguiente comando:
pip install 'git+https://github.com/facebookresearch/segment-anything.git'/content Collecting git+https://github.com/facebookresearch/segment-anything.git Cloning https://github.com/facebookresearch/segment-anything.git to /tmp/pip-req-build-xzlt_n7r Running command git clone --filter=blob:none --quiet https://github.com/facebookresearch/segment-anything.git /tmp/pip-req-build-xzlt_n7r Resolved https://github.com/facebookresearch/segment-anything.git to commit 6fdee8f2727f4506cfbbe553e23b895e27956588 Preparing metadata (setup.py) ... doneEl siguiente paso es descargar los pesos pre-entrenados del modelo SAM que deseas utilizar.
Puedes elegir entre tres opciones de pesos de checkpoints: ViT-B (91M), ViT-L (308M) y ViT-H (636M parámetros).
¿Cómo eliges el correcto? Cuanto mayor sea el número de parámetros, más tiempo se necesitará para la inferencia, es decir, la generación de máscaras. Si tienes pocos recursos de GPU y una inferencia rápida, elige ViT-B. De lo contrario, elige ViT-H.
Sigue los siguientes comandos para configurar la ruta del checkpoint del modelo:
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pthCHECKPOINT_PATH='/content/weights/sam_vit_h_4b8939.pth'import torchDEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')MODEL_TYPE = "vit_h"¡Los pesos del modelo están listos! Ahora, te mostraré diferentes métodos a través de los cuales puedes proporcionar indicaciones y generar máscaras en las próximas secciones. 🚀
Cómo SAM puede generar máscaras automáticamente
SAM puede segmentar automáticamente la imagen de entrada completa en segmentos distintos sin tener un indicador específico. Para esto, puedes usar la utilidad SamAutomaticMaskGenerator.
Sigue los siguientes comandos para importar e inicializarlo con el tipo de modelo y la ruta del checkpoint.
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictorsam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)mask_generator = SamAutomaticMaskGenerator(sam)Por ejemplo, he subido una imagen de perros a mi bloc de notas. Será nuestra imagen de entrada, que debe convertirse al formato de píxeles RGB (Rojo-Verde-Azul) para ser utilizada en el modelo.
Puedes hacer esto utilizando el paquete OpenCV en Python y luego utilizar la función generate() para crear una máscara, como se muestra a continuación:
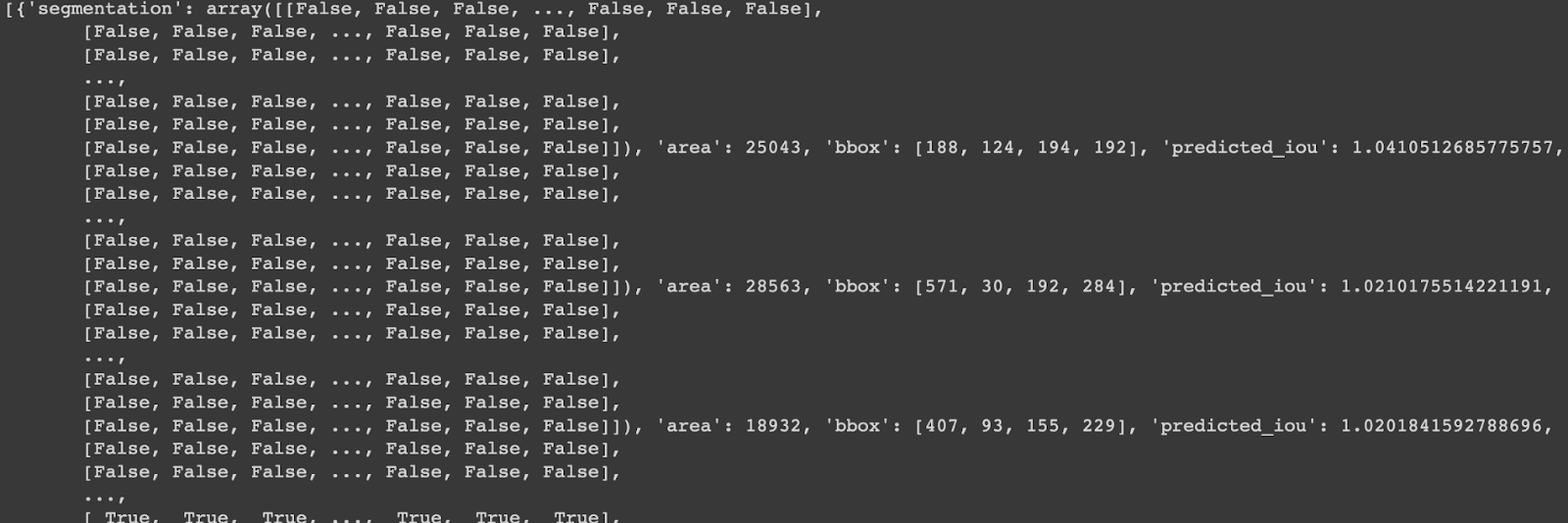
# Importar el paquete opencvinport cv2# Especifica la ruta de tu imagenIMAGE_PATH= '/content/dog.png'# Lee la imagen de la rutaimage= cv2.imread(IMAGE_PATH)# Conviértela al formato RGBimage_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# Generar la máscara de segmentaciónoutput_mask = mask_generator.generate(image_rgb)print(output_mask)La salida generada es un diccionario con los siguientes valores principales:
Segmentación:Un array que tiene una forma de máscaraárea:Un número entero que almacena el área de la máscara en píxelesbbox:Las coordenadas de la caja límite [xywh]Predicted_iou:IOU es un puntaje de evaluación para la segmentación
Entonces, ¿cómo visualizamos nuestra máscara de salida?
Bueno, es una función simple de Python que tomará el diccionario generado por SAM como salida y trazará las máscaras de segmentación con los valores de forma y coordenadas de la máscara.
# Función que ingresa la salida y traza la imagen y la máscara def show_output(result_dict, axes=None): if axes: ax = axes else: ax = plt.gca() ax.set_autoscale_on(False) sorted_result = sorted(result_dict, key=(lambda x: x['area']), reverse=True) # Plot for each segment area for val in sorted_result: mask = val['segmentation'] img = np.ones((mask.shape[0], mask.shape[1], 3)) color_mask = np.random.random((1, 3)).tolist()[0] for i in range(3): img[:,:,i] = color_mask[i] ax.imshow(np.dstack((img, mask*0.5)))Utilicemos esta función para trazar nuestra imagen de entrada en bruto y la máscara segmentada:
_,axes = plt.subplots(1,2, figsize=(16,16))axes[0].imshow(image_rgb)show_output(sam_result, axes[1])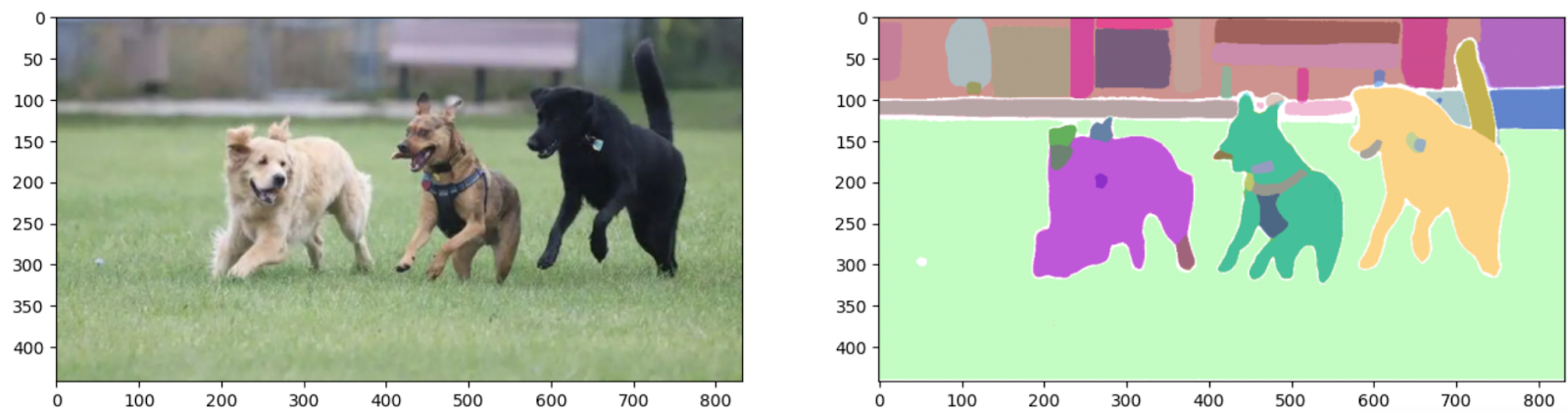
Como puedes ver, el modelo ha segmentado cada objeto en la imagen utilizando un método de cero disparos en un solo paso. 🌟
Cómo usar SAM con indicaciones de cuadro delimitador
A veces, es posible que deseemos segmentar solo una parte específica de una imagen. Para lograr esto, ingrese cuadros delimitadores aproximados para identificar el objeto dentro del área de interés, y SAM lo segmentará en consecuencia. Para implementar esto, importe e inicialice el SamPredictor y use la función set_image() para pasar la imagen de entrada. A continuación, llame a la función predict, proporcionando las coordenadas del cuadro delimitador como entrada para el parámetro box como se muestra en el fragmento a continuación. Las indicaciones del cuadro delimitador deben estar en el formato [X-min, Y-min, X-max, Y-max].
# Configure el modelo SAM con la imagen cifrada mask_predictor = SamPredictor(sam) mask_predictor.set_image(image_rgb) # Predecir máscara con indicación de cuadro delimitador máscaras, puntuaciones, logitos = mask_predictor.predict(box=bbox_prompt, multimask_output=False) # Trace el indicador del cuadro delimitador y la máscara predicha plt.imshow(image_rgb) show_mask(masks[0], plt.gca()) show_box(bbox_prompt, plt.gca()) plt.show() 
Cómo usar SAM con puntos como indicaciones
¿Qué pasa si necesita la máscara del objeto para un punto determinado en la imagen? Puede proporcionar las coordenadas del punto como una indicación de entrada a SAM. El modelo generará entonces las tres máscaras de segmentación más relevantes. Esto ayuda en caso de alguna ambigüedad sobre el objeto principal de interés.
Los primeros pasos son similares a lo que hicimos en las secciones anteriores. Inicialice el módulo predictor con la imagen de entrada. A continuación, proporcione la indicación de entrada como coordenadas [X, Y] al parámetro point_coords.
# Inicializar el modelo con la imagen de entrada from segment_anything import sam_model_registry, SamPredictorsam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)mask_predictor = SamPredictor(sam)mask_predictor.set_image(image_rgb)# Proporcionar puntos como indicación de entrada de coordenadas [X, Y] input_point = np.array([[250, 200]]) input_label = np.array([1]) # Predecir la máscara de segmentación en ese punto máscaras, puntuaciones, logitos = mask_predictor.predict(point_coords=input_point, point_labels=input_label, multimask_output=True,) Dado que hemos establecido el parámetro multimask_output como Verdadero, habrá tres máscaras de salida. Visualicémoslo trazando las máscaras y su indicador de entrada.

También he impreso las puntuaciones de IOU autoevaluadas para cada máscara. IOU significa Intersección sobre la Unión y mide la desviación entre el contorno del objeto y la máscara.
Conclusión
Puedes crear un conjunto de datos de segmentación adaptado para tu campo al recopilar imágenes en bruto y utilizar la herramienta SAM para la anotación. Este modelo ha demostrado un rendimiento consistente, incluso en condiciones difíciles como el ruido o la oclusión.
En la próxima versión, están haciendo que las indicaciones de texto sean compatibles, con el objetivo de mejorar la amigabilidad del usuario.
¡Espero que esta información te sea útil!
¡Gracias por leer! Soy Jess, una experta en Hyperskill. Puedes consultar nuestros cursos de ML en la plataforma.










Leave a Reply